Lenguajes De Interfaz
martes, 21 de mayo de 2019
Unidad 4: Operación y Mantenibilidad
4.1 Bitácoras de Trabajo del DBMS
Una bitácora (log) es una herramienta (archivos o registros) que permite registrar, analizar, detectar y notificar eventos que sucedan en cualquier sistema de información utilizado en las organizaciones.
La estructura más ampliamente usada para grabar las acciones que se llevan en la base de datos.
Nos ayuda a recuperar la información ante algunos incidentes de seguridad, detección de comportamiento inusual, información para resolver problemas, evidencia legal, es de gran ayuda en las tareas de computo forense.
Permite guardar las transacciones realizadas sobre una base de datos en específico, de tal manera que estas transacciones puedan ser auditadas y analizadas posteriormente.
Pueden obtenerse datos específicos de la transacción como:
1. Operación que se realizó
2. Usuario de BD
3. Fecha
4. Máquina
5. Programa
6. Tipo de conexión
7. Estado
No se requiere hacer cambios en los sistemas de producción o de desarrollo o en una simple instalación para la implementación de la bitácora.
A través de la parametrización se generan las pantallas de consulta y reportes sin necesidad de programar.
Acceso a la bitácora a través de una aplicación Web.
Control de Acceso a la información de la bitácora a través de Roles.
Se puede implementar en los sistemas de información que utilicen las principales bases de datos: Oracle, SQL Server, Informix, Sybase.
Permite hacer el seguimiento de todos los cambios que ha tenido un registro.
4.1.1 Funciones Específicas de las Bitácoras
La estructura más ampliamente usada para grabar las modificaciones de la base de datos es la Bitácora. Cada registro de la bitácora escribe una única escritura de base de datos y tiene lo siguiente:
· Nombre de la Transacción
Valor antiguo
Valor Nuevo
Es fundamental que siempre se cree un registro en la bitácora cuando se realice una escritura antes de que se modifique la base de datos.
También tenemos la posibilidad de deshacer una modificación que ya se ha escrito en la base de datos, esto se realizará usando el campo del valor antiguo de los registros de la bitácora.
Los registros de la bitácora deben residir en memoria estable como resultado el volumen de datos en la bitácora puede ser exageradamente grande.
Las operaciones COMMIT y ROLLBACK establecen lo que se le conoce como punto de sincronización lo cual representa el límite entre dos transacciones consecutivas, o el final de una unidad lógica de trabajo, y por tanto al punto en el cual la base de datos esta (o debería estar) en un estado de consistencia. Las únicas operaciones que establecen un punto de sincronización son COMMIT, ROLLBACK y el inicio de un programa. Cuando se establece un punto de sincronización:
Se comprometen o anulan todas las modificaciones realizadas por el programa desde el punto de sincronización anterior.
Se pierde todo posible posicionamiento en la base de datos. Se liberan todos los registros bloqueados. Es importante advertir que COMMIT y ROLLBACK terminan las transacción, no el programa.
4.1.2 Recuperación (Rollback)
En tecnologías de base de datos, un rollback es una operación que devuelve a la base de datos a algún estado previo. Los Rollbacks son importantes para la integridad de la base de datos, a causa de que significan que la base de datos puede ser restaurada a una copia limpia incluso después de que se han realizado operaciones erróneas. Son cruciales para la recuperación de crashes de un servidor de base de datos; realizando rollback (devuelto) cualquier transacción que estuviera activa en el tiempo del crash, la base de datos es restaurada a un estado consistente.
En SQL, ROLLBACK es un comando que causa que todos los cambios de datos desde la última sentencia BEGIN WORK, o START TRANSACTION sean descartados por el sistema de gestión de base de datos relacional (RDBMS), para que el estado de los datos sea "rolled back"(devuelto) a la forma en que estaba antes de que aquellos cambios tuvieran lugar.
Una sentencia ROLLBACK también publicará cualquier savepoint existente que puediera estar en uso.
En muchos dialectos de SQL, los ROLLBACK son específicos de la conexión. Esto significa que si se hicieron dos conexiones a la misma base de datos, un ROLLBACK hecho sobre una conexión no afectará a cualesquiera otras conexiones. Esto es vital para el buen funcionamiento de la Concurrencia.
La funcionalidad de rollback está normalmente implementada con un Log de transacciones, pero puede también estar implementada mediante control de concurrencia multiversión.
4.1.3 Permanencia (Commit)
En el contexto de la Ciencia de la computación y la gestión de datos, commit (acción de comprometer) se refiere a la idea de consignar un conjunto de cambios "tentativos, o no permanentes". Un uso popular es al final de una transacción de base de datos.
Una sentencia COMMIT en SQL finaliza una transacción de base de datos dentro de un sistema gestor de base de datos relacional (RDBMS) y pone visibles todos los cambios a otros usuarios. El formato general es emitir una sentencia BEGIN WORK, una o más sentencias SQL, y entonces la sentencia COMMIT. Alternativamente, una sentencia ROLLBACK se puede emitir, la cual deshace todo el trabajo realizado desde que se emitió BEGIN WORK. Una sentencia COMMIT publicará cualquiera de los savepoints (puntos de recuperación) existentes que puedan estar en uso.
En términos de transacciones, lo opuesto de commit para descartar los cambios "en tentativa" de una transacción, es un rollback.
4.2 Definición de los Modos de Operación de un DBMS (Alta, Baja, Recovery)
La vida de todo archivo comienza cuando se crea y acaba cuando se borra. Durante su existencia es objeto de constante procesamiento, que con mucha frecuencia incluye acciones de consulta o búsqueda y de actualización. En el caso de la estructura archivos, entenderemos como actualización, además de las operaciones, vistas para vectores y listas enlazadas, de introducir nuevos datos (altas) o de eliminar alguno existente (bajas), la modificación de datos ya existentes, (operación muy común con datos almacenados). En esencia, es la puesta al día de los datos del archivo.
Una operación de alta en un archivo consiste en la adición de un nuevo registro. En un archivo de empleados, un alta consistirá en introducir los datos de un nuevo empleado. Para situar correctamente un alta, se deberá conocer la posición donde se desea almacenar el registro correspondiente: al principio, en el interior o al final de un archivo.
El algoritmo de ALTAS debe contemplar la comprobación de que el registro a dar de alta no existe previamente. Una baja es la acción de eliminar un registro de un archivo. La baja de un registro puede ser lógica o física. Una baja lógica supone el no borrado del registro en el archivo. Esta baja lógica se manifiesta en un determinado campo del registro con una bandera, indicador o “flag” -carácter *. $, etc.,-, o bien con la escritura o rellenado de espacios en blanco en el registro dado de baja
Altas
La operación de dar de alta un determinado registro es similar a la de añadir datos a un archivo. Es importante remarcar que en un archivo secuencial sólo permite añadir datos al final del mismo.
En otro caso, si se quiere insertar un registro en medio de los ya presentes en el archivo, sería necesaria la creación nueva del archivo.
El algoritmo para dar de alta un registro al final del fichero es como sigue:
algoritmo altas
leer registro de alta
inicio
abrir archivo para añadir
mientras haya más registros hacer {algunos lenguajes ahorran este bucle}
leer datos del registro
fin_mientras
escribir (grabar) registro de alta en el archivo
cerrar archivo
fin
Bajas
Existen dos métodos para dar de baja a un registro en un archivo secuencial, donde no es fácil eliminar un registro situado en el interior de una secuencia: Para ello podemos seguir dos métodos:
1) Utilizar y por tanto crear un segundo archivo auxiliar transitorio, también secuencial, copia del que se trata de actualizar. Se lee el archivo completo registro a registro y en función de su lectura se decide si el registro se debe dar de baja o no. En caso afirmativo, se omite la escritura en el archivo auxiliar. Si el registro no se va a dar de baja, este registro se reescribe en el archivo auxiliar
Tras terminar la lectura del archivo original, se tendrán dos archivos: original (o maestro) y auxiliar. El proceso de bajas del archivo concluye borrando el archivo original y cambiando el nombre del archivo auxiliar por el del inicial.
2) Guardar o señalar los registros que se desean dar de baja con un indicador o bandera que se guarda en un array; de esta forma los registros no son borrados físicamente, sino que son considerados como inexistentes.
Inevitablemente, cada cierto tiempo, habrá que crear un nuevo archivo secuencial con el mismo nombre, en el que los registros marcados no se grabarán.
Propósito de Backup y Recuperación
Como administrador de copia de seguridad, la tarea principal es diseñar, implementar y gestionar una estrategia de backup y recuperación. En general, el propósito de una estrategia de recuperación de copia de seguridad y es para proteger la base de datos contra la pérdida de datos y reconstruir la base de datos después de la pérdida de datos. Normalmente, las tareas de administración de seguridad son las siguientes:
· Planificación y probar las respuestas a diferentes tipos de fallas.
· Configuración del entorno de base de datos de copia de seguridad y recuperación.
· La creación de un programa de copia de seguridad
· Seguimiento de la copia de seguridad y entorno de recuperación
· Solución de problemas de copia de seguridad
· Para recuperarse de la pérdida de datos en caso de necesidad
Como administrador de copia de seguridad, es posible que se le pida que realice otros deberes que se relacionan con copia de seguridad y recuperación:
· La preservación de datos, lo que implica la creación de una copia de base de datos para el almacenamiento a largo plazo
· La transferencia de datos, lo que implica el movimiento de datos de una base de datos o un host a otro.
De Protección de Datos
Como administrador de copia de seguridad, su trabajo principal es hacer copias de seguridad y vigilancia para la protección de datos. Una copia de seguridad es una copia de los datos de una base de datos que se puede utilizar para reconstruir los datos. Una copia de seguridad puede ser una copia de seguridad física o una copia de seguridad lógica.
Copias de seguridad físicas son copias de los archivos físicos utilizados en el almacenamiento y la recuperación de una base de datos. Estos archivos incluyen archivos de datos, archivos de control y los registros de rehacer archivados. En última instancia, cada copia de seguridad física es una copia de los archivos que almacenan información de base de datos a otra ubicación, ya sea en un disco o en medios de almacenamiento fuera de línea, tales como cinta.
Copias de seguridad lógicas contienen datos lógicos, como tablas y procedimientos almacenados. Puede utilizar Oracle Data Pump para exportar los datos a archivos lógicos binarios, que posteriormente puede importar a la base de datos. Clientes de línea de comandos La bomba datos expdp y impdp utilizan el DBMS_DATAPUMP y DBMS_METADATA PL / SQL paquetes.
Copias de seguridad físicas son la base de cualquier estrategia de recuperación de copia de seguridad sólida y. Copias de seguridad lógicas son un complemento útil de las copias de seguridad físicas en muchas circunstancias, pero no son suficiente protección contra la pérdida de datos y sin respaldos físicos.
A menos que se especifique lo contrario, la copia de seguridad término tal como se utiliza en la copia de seguridad y la documentación de recuperación se refiere a una copia de seguridad física. Copia de seguridad de una base de datos es el acto de hacer una copia de seguridad física. El enfoque en la copia de seguridad y recuperación de documentación está casi exclusivamente en copias de seguridad físicas.
Mientras que varios problemas pueden detener el funcionamiento normal de una base de datos Oracle o afectar a las operaciones de base de datos de E / S, solamente la siguiente normalmente requiere la intervención del DBA y de recuperación de datos: un error de medios, errores de usuario, y los errores de aplicación. Otros fallos pueden requerir intervención DBA sin causar la pérdida de datos o que requieren la recuperación de copia de seguridad. Por ejemplo, es posible que tenga que reiniciar la base de datos tras un fallo de instancia o asignar más espacio de disco después de un fallo debido a la declaración de un archivo de datos completo.
Las Fallas de Medios
La falta de medios es un problema físico con un disco que provoca un fallo de una leer o escribir en un archivo de disco que se requiere para ejecutar la base de datos. Cualquier archivo de base de datos puede ser vulnerable a un fallo de comunicación. La técnica de recuperación adecuada después de un fallo de los medios de comunicación depende de los archivos afectados y el tipo de copia de seguridad disponible.
Un aspecto particularmente importante de la copia de seguridad y recuperación se está desarrollando una estrategia de recuperación ante desastres para proteger contra la pérdida de datos catastrófica, por ejemplo, la pérdida de toda una serie de bases de datos.
Errores de los Usuarios
Los errores del usuario cuando se producen, ya sea debido a un error en la lógica de la aplicación o un error manual, los datos en una base de datos se modifican o eliminan incorrectamente. Errores de usuario se estima que la mayor causa de inactividad de base de datos.
La pérdida de datos debido a un error del usuario puede ser localizada o generalizada. Un ejemplo de daño localizado está eliminando a la persona equivocada en la tabla empleados. Este tipo de lesiones requiere la detección y la reparación quirúrgica. Un ejemplo de un daño generalizado es un trabajo por lotes que borra las órdenes de la empresa para el mes en curso. En este caso, se requiere una acción drástica para evitar una extensa base de datos de tiempo de inactividad.
Mientras que la formación de usuarios y el manejo cuidadoso de los privilegios pueden prevenir la mayoría de los errores de usuario, su estrategia de copia de seguridad determina la gracia de recuperar los datos perdidos cuando un error del usuario que hace perder los datos.
Errores de Aplicación
A veces, un mal funcionamiento de software puede dañar los bloques de datos. En una corrupción física, que también se conoce como la corrupción los medios de comunicación, la base de datos no reconoce el bloque en absoluto: la suma de comprobación no es válida, el bloque contiene todos los ceros, o el encabezado y el pie de página del bloque no coinciden. Si el daño no es muy amplio, puede a menudo repara fácilmente con bloque de recuperación de medios.
Preservación de Datos
Conservación de datos se relaciona con la protección de datos, pero tiene un propósito diferente. Por ejemplo, puede que tenga que conservar una copia de una base de datos tal como existía al final de la cuarta parte del negocio. Esta copia de seguridad no es parte de la estrategia de recuperación de desastres. Los medios a los que estas copias de seguridad se escriben a menudo disponible después de la copia de seguridad. Usted puede enviar la cinta en almacenamiento incendio o enviar un disco duro portátil a un centro de pruebas. RMAN proporciona una manera conveniente para crear una copia de seguridad y eximirla de su política de retención de copia de seguridad. Este tipo de copia de seguridad se conoce como una copia de seguridad de archivo.
Transferencia de Datos
En algunas situaciones, es posible que tenga que tomar una copia de seguridad de una base de datos o base de datos de componentes y moverlo a otra ubicación. Por ejemplo, puede utilizar el Administrador de recuperación (RMAN) para crear una copia de base de datos, cree una copia de tabla que se puede importar en otra base de datos, o mover una base de datos completa de una plataforma a otra. Estas tareas no son, estrictamente hablando, parte de una estrategia de backup y recuperación, pero requieren el uso de copias de seguridad de bases de datos, por lo que pueden incluirse en las tareas de un administrador de copia de seguridad.
Oracle Backup y Recuperación de Soluciones
Al implementar una estrategia de backup y recuperación, dispone de las siguientes soluciones disponibles:
· Administrador de Recuperación (RMAN)
Recovery Manager está completamente integrado con la base de datos Oracle para llevar a cabo una serie de actividades de copia de seguridad y recuperación, incluyendo el mantenimiento de un repositorio de RMAN de datos históricos acerca de las copias de seguridad. Se puede acceder a RMAN través de la línea de comandos oa través de Oracle Enterprise Manager.
· Copia de Seguridad y Recuperación Gestionadas por el Usuario
En esta solución, realizar copias de seguridad y recuperación con una mezcla de comandos del sistema operativo host y SQL * Plus.
Recuperación de Comandos
Ustedes son responsables de determinar todos los aspectos de cuándo y cómo las copias de seguridad y la recuperación se hacen.
Estas soluciones están respaldadas por Oracle y se documentan, pero RMAN es la mejor solución para copia de seguridad y recuperación de bases de datos. RMAN proporciona una interfaz común para las tareas de copia de seguridad a través de diferentes sistemas operativos host, y ofrece varias técnicas de copia de seguridad que no están disponibles a través de métodos administrados por usuarios.
La mayor parte de este manual se centra en la copia de seguridad y recuperación de RMAN basado. Técnicas de copia de seguridad y recuperación gestionadas por el usuario se tratan en Realización de usuario-Managed Backup and Recovery. Las más destacables son los siguientes:
· Copias de Seguridades Incrementales
Una copia de seguridad incremental almacena sólo los bloques modificados desde la última copia de seguridad. Por lo tanto, proporcionan copias de seguridad más compacta y una recuperación más rápida, lo que reduce la necesidad de aplicar de rehacer en archivo de datos de recuperación de los medios de comunicación. Si se habilita el seguimiento de cambios de bloque, entonces usted puede mejorar el rendimiento al evitar escaneos completos de todos los archivos de datos de entrada. Utilice el comando Copia de seguridad incremental para realizar copias de seguridad incrementales.
· Bloquear los Medios de Recuperación
Usted puede reparar un archivo de datos con sólo un pequeño número de bloques de datos corruptos sin tomarlo fuera de línea o la restauración desde copia de seguridad. Utilice el comando BLOQUE RECOVER para realizar la recuperación del bloque de comunicación.
· Compresión Binaria
Un mecanismo de compresión binaria integrado en base de datos Oracle reduce el tamaño de las copias de seguridad.
· Copias de Seguridad Encriptadas
RMAN utiliza las capacidades de cifrado de copia de seguridad integrados en bases de datos Oracle para almacenar conjuntos de copia de seguridad en un formato codificado. Para crear copias de seguridad cifradas en el disco, la base de datos debe utilizar la opción de seguridad avanzada. Para crear copias de seguridad encriptadas directamente en cinta, RMAN debe utilizar la copia de seguridad de Oracle Secure interfaz SBT, pero no requiere la opción de seguridad avanzada.
· Duplicación de la Base de Datos Automatizada
Crea fácilmente una copia de su base de datos, el apoyo a diversas configuraciones de almacenamiento, incluida la duplicación directa entre las bases de datos de ASM.
· Conversión de Datos entre Plataformas
Ya sea que utilice RMAN o métodos administrados por usuarios, puede complementar las copias de seguridad físicas con copias de seguridad lógicas de objetos de esquema realizados con la utilidad Export Data Pump. Más tarde, puede utilizar Data Pump Import para volver a crear los datos después de la restauración y la recuperación. Copias de seguridad lógicas son en su mayoría más allá del alcance de la copia de seguridad y de recuperación de documentación.
4.3 Comandos de Activación para los Modos de Operación
Para ser uso de los diferentes comandos para un modo de operación debemos estar como administrador o asuma un rol que incluya el perfil de derechos Service Management.
Comando STARTUP
Para el arranque de una base de datos hay tres fases de arranque, para realizar estas fases podemos utilizar startup más un comando, las tres fases son las siguientes:
Fase de no Montaje: se leen los parámetros del sistema, se inician las estructuras de memoria y los procesos de segundo plano. La instancia se arranca sin asociarla a la base de datos. Normalmente se utiliza cuando se modifica o se necesita crear el archivo de control:
startup nomount ;
Fase de Montaje: se asocia la instancia con la base de datos. Se usa el archivo de parámetros para localizar los archivos de control, que contienen el nombre de los archivos de datos y los registros rehacer. Los archivos de datos y los registros de rehacer no están abiertos, así que no son accesibles por usuarios finales para tareas normales. Para realizar esta fase se pueden utilizar dos comandos:
startup mount;
alter database mount;
Fase de Apertura: se abren los archivos de datos y los registros rehacer. La base de datos queda disponible para las operaciones normales. Es necesario que existan registros rehacer de lo contrario si no hay registros usamos el comando resetlogs, que crea registros nuevos. Para esta fase se pueden usar dos comandos:
startup open;
alter database open;
Si es necesario utilizar resetlogs:
startup open resetlogs;
alter database open resetlogs;
startup restrict (sólo permite la conexión de usuarios con el privilegio restricted sesion).
startup force (hace shutdown abort y arranca la BD).
Comando SHUTDOWN
El comando SHUTDOWN lo utilizamos parar una base de datos la cual consiste en varias cláusulas.
Shutdown Normal: Este es el valor por defecto, durante el proceso de parada no admite nuevas conexiones y espera que las conexiones actuales finalicen. En el próximo arranque la base datos no requiere procedimientos de recuperación.
Shutdown Immediate: Se produce una parada inmediata de la base de datos, durante el proceso de parada no permite nuevas conexiones y las actuales la desconecta, las transacciones que no estén commit se hara roolback de ellas. En el próximo arranque la base datos no requiere procedimientos de recuperación.
Shutdown Transactional: Se produce una parada hasta que hayan terminado las transacciones activas, no admite nuevas conexiones y tampoco nuevas transacciones, una vez que las transacciones activas van terminando va desconectando a los usuarios. En el próximo arranque la base datos no requiere procedimientos de recuperación.
Shutdown Abort: Aborta todos los procesos de una base de datos, durante el proceso de parada no permite nuevas conexiones y las actuales la desconecta, las transacciones que no estén commit se hará roolback de ellas. En el próximo arranque la base datos puede requerir procedimientos de recuperación.
Comando Describe
Este comando permite conocer la estructura de una tabla, las columnas que la forman y su tipo y restricciones.
DESCRIBE f1;
Comando SHOW TABLES y SHOW CREATE TABLE
El comando SHOW TABLES muestra las tablas dentro de una base de datos y SHOW CREATE TABLES muestra la estructura de creación de la tabla.
Modificación
Para realizar una modificación utilizamos el comando ALTER TABLE. Para usar ALTER TABLE, necesita permisos ALTER, INSERT y CREATE para la tabla.
4.4.- Manejo de Índices
El índice de una base de datos es una estructura alternativa de los datos en una tabla. El propósito de los índices es acelerar el acceso a los datos mediante operaciones físicas más rápidas y efectivas. En pocas palabras, se mejoran las operaciones gracias a un aumento de la velocidad, permitiendo un rápido acceso a los registros de una tabla en una base de datos. Al aumentar drásticamente la velocidad de acceso, se suelen usar sobre aquellos campos sobre los cuáles se hacen búsquedas frecuentes.
4.4.1 Tipos de Índices
Resumen de Índices
Un índice es una estructura opcional, asociado con una mesa o tabla de clúster, que a veces puede acelerar el acceso de datos. Mediante la creación de un índice en una o varias columnas de una tabla, se obtiene la capacidad en algunos casos, para recuperar un pequeño conjunto de filas distribuidas al azar de la tabla. Los índices son una de las muchas formas de reducir el disco I / O.
Si una tabla de montón organizado no tiene índices, entonces la base de datos debe realizar un escaneo completo de tabla para encontrar un valor. Por ejemplo, sin un índice, una consulta de ubicación 2700 en la tabla hr.departments requiere la base de datos para buscar todas las filas de cada bloque de la tabla para este valor. Este enfoque no escala bien como datos de aumento de volúmenes.
Por analogía, supongamos que un gerente de Recursos Humanos tiene un estante de cajas de cartón. Las carpetas que contienen información de los empleados se insertan aleatoriamente en las cajas. La carpeta de empleado Whalen (ID 200) es de 10 carpetas desde el fondo de la caja 1, mientras que la carpeta para el rey (ID 100) se encuentra en la parte inferior del cuadro 3. Para localizar una carpeta, el gestor busca en cada carpeta en la casilla 1 de abajo hacia arriba, y luego se mueve de una casilla a otra hasta que se encuentra la carpeta. Para acelerar el acceso, el administrador puede crear un índice que enumera de forma secuencial todos los ID de empleado con su ubicación de la carpeta:
ID 100: Box 3, position 1 (bottom)
ID 101: Box 7, position 8
ID 200: Box 1, position 10
Del mismo modo, el administrador podría crear índices separados para los últimos nombres de los empleados, los ID de departamento, y así sucesivamente.
En general, considerar la creación de un índice en una columna en cualquiera de las siguientes situaciones:
· Las columnas indizadas se consultan con frecuencia y devuelven un pequeño porcentaje del número total de filas en la tabla.
· Existe una restricción de integridad referencial en la columna o columnas indexadas. El índice es un medio para evitar un bloqueo de tabla completa que de otro modo se requeriría si se actualiza la clave principal de la tabla principal, se funden en la tabla principal, o eliminar de la tabla primaria.
· Una restricción de clave única se coloca sobre la mesa y desea especificar manualmente el índice de todas las opciones sobre índices y.
Características de Indexación
Los índices son objetos de esquema que son lógica y físicamente independiente de los datos de los objetos con los que están asociados. Por lo tanto, un índice se puede quitar o creado sin afectar físicamente a la tabla para el índice.
Nota: Si se le cae un índice, las aplicaciones siguen funcionando. Sin embargo, el acceso de los datos previamente indexado puede ser más lento.
La ausencia o presencia de un índice no requiere un cambio en el texto de cualquier sentencia SQL. Un índice es una ruta de acceso rápido a una sola fila de datos. Sólo afecta a la velocidad de ejecución. Dado un valor de datos que se ha indexado, el índice apunta directamente a la ubicación de las filas que contienen ese valor.
La base de datos mantiene automáticamente y utiliza los índices después de su creación. La base de datos también refleja automáticamente los cambios en los datos, como agregar, actualizar y eliminar filas, en todos los índices pertinentes sin acciones adicionales requeridas por los usuarios. Rendimiento de recuperación de datos indexados permanece casi constante, incluso cuando se insertan filas. Sin embargo, la presencia de muchos índices en una tabla degrada el rendimiento DML porque la base de datos también debe actualizar los índices.
Los índices tienen las siguientes propiedades:
· Facilidad de Uso
Los índices son utilizables (por defecto) o inutilizable. Un índice inutilizables no se mantiene por las operaciones DML y es ignorado por el optimizador. Un índice inutilizable puede mejorar el rendimiento de las cargas a granel. En lugar de dejar un índice y luego volverlo a crear, puede hacer que el índice inservible y luego reconstruirlo. Índices inutilizables y las particiones de índice no consumen espacio. Cuando usted hace un índice utilizable no utilizable, la base de datos cae su segmento de índice.
· Visibilidad
Los índices son visibles (por defecto) o invisible. Un índice invisible se mantiene por las operaciones DML y no se utiliza de forma predeterminada por el optimizador. Cómo hacer una invisible índice es una alternativa a lo que es inutilizable o se caiga. Índices invisibles son especialmente útiles para probar la eliminación de un índice antes de dejarlo caer o mediante índices temporalmente sin afectar a la aplicación general.
Guía del Administrador para Aprender a Manejar los Índices
· Base de datos Oracle Performance Tuning Guide para aprender cómo ajustar los índices
Teclas y Columnas
Una clave es un conjunto de columnas o expresiones en las que se puede construir un índice. Aunque los términos se usan indistintamente, los índices y las claves son diferentes. Los índices son estructuras almacenados en la base de datos que los usuarios a administrar el uso de sentencias de SQL. Las claves son estrictamente un concepto lógico.
La siguiente sentencia crea un índice en la columna customer_id de la muestra oe.orders tabla:
CREATE INDEX ord_customer_ix ON orders (customer_id);
En la declaración anterior, la columna customer_id es la clave de índice. El índice en sí se llama ord_customer_ix.
Índices Compuestos
Un índice compuesto, también llamado índice concatenado, es un índice de varias columnas de una tabla. Las columnas de un índice compuesto que deben aparecer en el orden que tenga más sentido para las consultas que recuperar datos y no necesita ser adyacente en la tabla.
Los índices compuestos pueden acelerar la recuperación de datos para las instrucciones SELECT en la que el DONDE referencias cláusula totalidad o la parte principal de las columnas en el índice compuesto. Por lo tanto, el orden de las columnas utilizadas en la definición es importante. En general, las columnas de acceso más común van primero.
Por ejemplo, supongamos que una aplicación realiza consultas frecuentes a apellidos, job_id, y columnas de salario en la tabla empleados. También asumir que last_name tiene alta cardinalidad, lo que significa que el número de valores distintos que es grande en comparación con el número de filas de la tabla. Se crea un índice con el siguiente orden de las columnas:
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);
Las consultas que acceden a las tres columnas, sólo la columna last_name, o sólo el last_name y columnas job_id utilizan este índice. En este ejemplo, las consultas que no tienen acceso a la columna last_name no utilizan el índice.
Nota: En algunos casos, tales como cuando la columna principal tiene muy baja cardinalidad, la base de datos puede utilizar una búsqueda selectiva de este índice.
Múltiples índices pueden existir para la misma mesa, siempre y cuando la permutación de columnas difiere para cada índice. Puede crear varios índices que utilizan las mismas columnas si se especifica claramente diferentes permutaciones de las columnas. Por ejemplo, las siguientes sentencias SQL especifican permutaciones válidas:
CREATE INDEX employee_idx1 ON employees (last_name, job_id);
CREATE INDEX employee_idx2 ON employees (job_id, last_name);
Índices Únicos y no Únicos
Los índices pueden ser únicos o no únicos. Índices únicos garantizar que no hay dos filas de una tabla tienen valores duplicados en la columna de clave o columna. Por ejemplo, dos empleados no pueden tener el mismo ID de empleado. Por lo tanto, en un índice único, existe una ROWID para cada valor de datos. Los datos de los bloques de hojas se ordenan sólo por clave.
Índices no únicas permiten valores duplicados en la columna o columnas indexadas. Por ejemplo, la columna 'nombre de la tabla de empleados puede contener varios valores Mike. Para un índice no único, el ROWID se incluye en la clave de forma ordenada, por lo que los índices no únicos se ordenan por la clave de índice y ROWID (ascendente).
Oracle Database no filas de la tabla de índice en el que todas las columnas clave son nulas, a excepción de los índices de mapa de bits o cuando el valor de la columna clave de clúster es nulo.
Tipos de Índices
Base de Datos Oracle ofrece varias combinaciones de indexación, que proporcionan una funcionalidad complementaria sobre el rendimiento. Los índices se pueden clasificar de la siguiente manera:
· Los Índices de Árbol B
Estos índices son el tipo de índice estándar. Son excelentes para la clave principal y los índices altamente selectivos. Utilizado como índices concatenados, B-tree índice pueden recuperar los datos ordenados por las columnas de índice. Índices B-tree tienen los siguientes subtipos:
· Índice de Tablas Organizadas
Una tabla de índice-organizada difiere de un montón-organizado porque los datos es en sí mismo el índice.
En este tipo de índice, los bytes de la clave de índice se invierten, por ejemplo, 103 se almacena como 301. La inversión de bytes extiende inserta en el índice durante muchos bloques.
· Índices Descendentes
Este tipo de índice almacena los datos en una columna o columnas de concreto en orden descendente.
· Índices B-Tree de Racimo
Este tipo de índice se utiliza para indexar una clave de clúster tabla. En lugar de apuntar a una fila, los puntos clave para el bloque que contiene filas relacionadas con la clave de clúster.
· Mapa de Bits y los Índices Bitmap Join
En un índice de mapa de bits, una entrada de índice utiliza un mapa de bits para que apunte a varias filas. En cambio, los puntos de entrada de un índice B-tree en una sola fila. Un índice de combinación de mapa de bits es un índice de mapa de bits para la unión de dos o más tablas. Consulte "Indicadores de mapa de bits".
· Índices Basados en Funciones
Este tipo de índice incluye columnas que, o bien se transforman por una función, tales como la función UPPER, o incluidos en una expresión. Índices B-tree o mapa de bits puede ser basado en las funciones.
· Índices de Dominio de Aplicación
Este tipo de índice se crea por un usuario para los datos en un dominio específico de la aplicación. El índice físico no tiene que utilizar una estructura de índice tradicional y se puede almacenar ya sea en la base de datos Oracle como tablas o externamente como un archivo. Consulte "Indicadores de dominio de aplicación".
· Índices B-Tree
Árboles B, abreviatura de árboles balanceados, son el tipo más común de índice de base de datos. Un índice B-tree es una lista ordenada de valores dividida en rangos. Mediante la asociación de una tecla con una fila o rango de filas, los árboles B proporcionan un excelente rendimiento de la recuperación para una amplia gama de consultas, incluyendo coincidencia exacta y búsquedas por rango.
La figura 3-1 ilustra la estructura de un índice B-tree. El ejemplo muestra un índice en la columna department_id, que es una columna de clave externa en la tabla empleados.
4.4.2 Reorganización de Índices.
Un factor clave para conseguir una E/S de disco mínima para todas las consultas de bases de datos es asegurarse de que se creen y se mantengan buenos índices. Una vez creados los índices, se debe procurar mantenerlos para asegurarse que sigan trabajando en forma óptima. A medida que se agregan, modifican o borran datos se produce fragmentación. Esta fragmentación puede ser buena o mala para el rendimiento del sistema, dependiendo de las necesidades del trabajo de la base de datos.
Fragmentación de los Índices
La fragmentación es consecuencia de los procesos de modificación de los datos (instrucciones INSERT, UPDATE y DELETE) efectuados en la tabla y en los índices definidos en la tabla. Como dichas modificaciones no suelen estar distribuidas de forma equilibrada entre las filas de la tabla y los índices, el llenado de cada página puede variar con el paso del tiempo. Para las consultas que recorren parcial o totalmente los índices de una tabla, este tipo de fragmentación puede producir lecturas de páginas adicionales. Esto impide el recorrido paralelo de los datos. Existen dos tipos de fragmentación:
Interna: Fragmentación dentro de páginas individuales de datos e índices con espacios libres que generan la necesidad de más operaciones de E/S y más memoria para su lectura. Este hecho disminuye el rendimiento en ambientes de lectura, pero en algunos casos puede beneficiar las inserciones, que no requieren una división de páginas con tanta frecuencia.
Externa: Cuando el orden lógico de las páginas no es correcto, porque las páginas no son contiguas. El acceso a los datos es mucho más lento por la necesidad de búsqueda de los datos.
La fragmentación de índices se puede reparar reorganizando un índice o reconstruyéndolo. Para los índices fraccionados que fueron construidos en una estructura partida se puede usar cualquiera de estos métodos o bien en un índice completo o bien en un único fragmento del índice.
Detección de Fragmentación
El primer paso para decidir qué método de desfragmentación se va a utilizar consiste en analizar el índice para determinar el nivel de fragmentación. Si se usa la función del sistema sys.dm_db_index_physical_stats, se puede detectar la fragmentación de los índices de la base de datos thuban-homologada.
SELECT DISTINCT
A.INDEX_ID 'IDIndice';
sys.TABLES.name 'Tabla',
b.name 'Indice',
avg_fragmentation_in_percentr '% Fragmentación',
fragment_count 'Cantidad de Fragmentos',
avg_fragment_size_in_pages 'Promedio de fragmentos por página',
FROM
sys.dm_db_index_physical_stats (
DB_ID ()N'thuban-himologada'),
OBJECT_ID (N'dbo.*'),
NULL,
NULL,
NULL) AS a JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id,
sys.TABLES
WHERE
sys.TABLES.object_id = b.object_id
ORDER BY
avg_fragmentation_in_percent DESC
La grilla de resultados emitida por la anterior sentencia incluye las siguientes columnas:

Una bitácora (log) es una herramienta (archivos o registros) que permite registrar, analizar, detectar y notificar eventos que sucedan en cualquier sistema de información utilizado en las organizaciones.
La estructura más ampliamente usada para grabar las acciones que se llevan en la base de datos.
Nos ayuda a recuperar la información ante algunos incidentes de seguridad, detección de comportamiento inusual, información para resolver problemas, evidencia legal, es de gran ayuda en las tareas de computo forense.
Permite guardar las transacciones realizadas sobre una base de datos en específico, de tal manera que estas transacciones puedan ser auditadas y analizadas posteriormente.
Pueden obtenerse datos específicos de la transacción como:
1. Operación que se realizó
2. Usuario de BD
3. Fecha
4. Máquina
5. Programa
6. Tipo de conexión
7. Estado
No se requiere hacer cambios en los sistemas de producción o de desarrollo o en una simple instalación para la implementación de la bitácora.
A través de la parametrización se generan las pantallas de consulta y reportes sin necesidad de programar.
Acceso a la bitácora a través de una aplicación Web.
Control de Acceso a la información de la bitácora a través de Roles.
Se puede implementar en los sistemas de información que utilicen las principales bases de datos: Oracle, SQL Server, Informix, Sybase.
Permite hacer el seguimiento de todos los cambios que ha tenido un registro.
4.1.1 Funciones Específicas de las Bitácoras
La estructura más ampliamente usada para grabar las modificaciones de la base de datos es la Bitácora. Cada registro de la bitácora escribe una única escritura de base de datos y tiene lo siguiente:
· Nombre de la Transacción
Valor antiguo
Valor Nuevo
Es fundamental que siempre se cree un registro en la bitácora cuando se realice una escritura antes de que se modifique la base de datos.
También tenemos la posibilidad de deshacer una modificación que ya se ha escrito en la base de datos, esto se realizará usando el campo del valor antiguo de los registros de la bitácora.
Los registros de la bitácora deben residir en memoria estable como resultado el volumen de datos en la bitácora puede ser exageradamente grande.
Las operaciones COMMIT y ROLLBACK establecen lo que se le conoce como punto de sincronización lo cual representa el límite entre dos transacciones consecutivas, o el final de una unidad lógica de trabajo, y por tanto al punto en el cual la base de datos esta (o debería estar) en un estado de consistencia. Las únicas operaciones que establecen un punto de sincronización son COMMIT, ROLLBACK y el inicio de un programa. Cuando se establece un punto de sincronización:
Se comprometen o anulan todas las modificaciones realizadas por el programa desde el punto de sincronización anterior.
Se pierde todo posible posicionamiento en la base de datos. Se liberan todos los registros bloqueados. Es importante advertir que COMMIT y ROLLBACK terminan las transacción, no el programa.
4.1.2 Recuperación (Rollback)
En tecnologías de base de datos, un rollback es una operación que devuelve a la base de datos a algún estado previo. Los Rollbacks son importantes para la integridad de la base de datos, a causa de que significan que la base de datos puede ser restaurada a una copia limpia incluso después de que se han realizado operaciones erróneas. Son cruciales para la recuperación de crashes de un servidor de base de datos; realizando rollback (devuelto) cualquier transacción que estuviera activa en el tiempo del crash, la base de datos es restaurada a un estado consistente.
En SQL, ROLLBACK es un comando que causa que todos los cambios de datos desde la última sentencia BEGIN WORK, o START TRANSACTION sean descartados por el sistema de gestión de base de datos relacional (RDBMS), para que el estado de los datos sea "rolled back"(devuelto) a la forma en que estaba antes de que aquellos cambios tuvieran lugar.
Una sentencia ROLLBACK también publicará cualquier savepoint existente que puediera estar en uso.
En muchos dialectos de SQL, los ROLLBACK son específicos de la conexión. Esto significa que si se hicieron dos conexiones a la misma base de datos, un ROLLBACK hecho sobre una conexión no afectará a cualesquiera otras conexiones. Esto es vital para el buen funcionamiento de la Concurrencia.
La funcionalidad de rollback está normalmente implementada con un Log de transacciones, pero puede también estar implementada mediante control de concurrencia multiversión.
4.1.3 Permanencia (Commit)
En el contexto de la Ciencia de la computación y la gestión de datos, commit (acción de comprometer) se refiere a la idea de consignar un conjunto de cambios "tentativos, o no permanentes". Un uso popular es al final de una transacción de base de datos.
Una sentencia COMMIT en SQL finaliza una transacción de base de datos dentro de un sistema gestor de base de datos relacional (RDBMS) y pone visibles todos los cambios a otros usuarios. El formato general es emitir una sentencia BEGIN WORK, una o más sentencias SQL, y entonces la sentencia COMMIT. Alternativamente, una sentencia ROLLBACK se puede emitir, la cual deshace todo el trabajo realizado desde que se emitió BEGIN WORK. Una sentencia COMMIT publicará cualquiera de los savepoints (puntos de recuperación) existentes que puedan estar en uso.
En términos de transacciones, lo opuesto de commit para descartar los cambios "en tentativa" de una transacción, es un rollback.
4.2 Definición de los Modos de Operación de un DBMS (Alta, Baja, Recovery)
La vida de todo archivo comienza cuando se crea y acaba cuando se borra. Durante su existencia es objeto de constante procesamiento, que con mucha frecuencia incluye acciones de consulta o búsqueda y de actualización. En el caso de la estructura archivos, entenderemos como actualización, además de las operaciones, vistas para vectores y listas enlazadas, de introducir nuevos datos (altas) o de eliminar alguno existente (bajas), la modificación de datos ya existentes, (operación muy común con datos almacenados). En esencia, es la puesta al día de los datos del archivo.
Una operación de alta en un archivo consiste en la adición de un nuevo registro. En un archivo de empleados, un alta consistirá en introducir los datos de un nuevo empleado. Para situar correctamente un alta, se deberá conocer la posición donde se desea almacenar el registro correspondiente: al principio, en el interior o al final de un archivo.
El algoritmo de ALTAS debe contemplar la comprobación de que el registro a dar de alta no existe previamente. Una baja es la acción de eliminar un registro de un archivo. La baja de un registro puede ser lógica o física. Una baja lógica supone el no borrado del registro en el archivo. Esta baja lógica se manifiesta en un determinado campo del registro con una bandera, indicador o “flag” -carácter *. $, etc.,-, o bien con la escritura o rellenado de espacios en blanco en el registro dado de baja
Altas
La operación de dar de alta un determinado registro es similar a la de añadir datos a un archivo. Es importante remarcar que en un archivo secuencial sólo permite añadir datos al final del mismo.
En otro caso, si se quiere insertar un registro en medio de los ya presentes en el archivo, sería necesaria la creación nueva del archivo.
El algoritmo para dar de alta un registro al final del fichero es como sigue:
algoritmo altas
leer registro de alta
inicio
abrir archivo para añadir
mientras haya más registros hacer {algunos lenguajes ahorran este bucle}
leer datos del registro
fin_mientras
escribir (grabar) registro de alta en el archivo
cerrar archivo
fin
Bajas
Existen dos métodos para dar de baja a un registro en un archivo secuencial, donde no es fácil eliminar un registro situado en el interior de una secuencia: Para ello podemos seguir dos métodos:
1) Utilizar y por tanto crear un segundo archivo auxiliar transitorio, también secuencial, copia del que se trata de actualizar. Se lee el archivo completo registro a registro y en función de su lectura se decide si el registro se debe dar de baja o no. En caso afirmativo, se omite la escritura en el archivo auxiliar. Si el registro no se va a dar de baja, este registro se reescribe en el archivo auxiliar
Tras terminar la lectura del archivo original, se tendrán dos archivos: original (o maestro) y auxiliar. El proceso de bajas del archivo concluye borrando el archivo original y cambiando el nombre del archivo auxiliar por el del inicial.
2) Guardar o señalar los registros que se desean dar de baja con un indicador o bandera que se guarda en un array; de esta forma los registros no son borrados físicamente, sino que son considerados como inexistentes.
Inevitablemente, cada cierto tiempo, habrá que crear un nuevo archivo secuencial con el mismo nombre, en el que los registros marcados no se grabarán.
Propósito de Backup y Recuperación
Como administrador de copia de seguridad, la tarea principal es diseñar, implementar y gestionar una estrategia de backup y recuperación. En general, el propósito de una estrategia de recuperación de copia de seguridad y es para proteger la base de datos contra la pérdida de datos y reconstruir la base de datos después de la pérdida de datos. Normalmente, las tareas de administración de seguridad son las siguientes:
· Planificación y probar las respuestas a diferentes tipos de fallas.
· Configuración del entorno de base de datos de copia de seguridad y recuperación.
· La creación de un programa de copia de seguridad
· Seguimiento de la copia de seguridad y entorno de recuperación
· Solución de problemas de copia de seguridad
· Para recuperarse de la pérdida de datos en caso de necesidad
Como administrador de copia de seguridad, es posible que se le pida que realice otros deberes que se relacionan con copia de seguridad y recuperación:
· La preservación de datos, lo que implica la creación de una copia de base de datos para el almacenamiento a largo plazo
· La transferencia de datos, lo que implica el movimiento de datos de una base de datos o un host a otro.
De Protección de Datos
Como administrador de copia de seguridad, su trabajo principal es hacer copias de seguridad y vigilancia para la protección de datos. Una copia de seguridad es una copia de los datos de una base de datos que se puede utilizar para reconstruir los datos. Una copia de seguridad puede ser una copia de seguridad física o una copia de seguridad lógica.
Copias de seguridad físicas son copias de los archivos físicos utilizados en el almacenamiento y la recuperación de una base de datos. Estos archivos incluyen archivos de datos, archivos de control y los registros de rehacer archivados. En última instancia, cada copia de seguridad física es una copia de los archivos que almacenan información de base de datos a otra ubicación, ya sea en un disco o en medios de almacenamiento fuera de línea, tales como cinta.
Copias de seguridad lógicas contienen datos lógicos, como tablas y procedimientos almacenados. Puede utilizar Oracle Data Pump para exportar los datos a archivos lógicos binarios, que posteriormente puede importar a la base de datos. Clientes de línea de comandos La bomba datos expdp y impdp utilizan el DBMS_DATAPUMP y DBMS_METADATA PL / SQL paquetes.
Copias de seguridad físicas son la base de cualquier estrategia de recuperación de copia de seguridad sólida y. Copias de seguridad lógicas son un complemento útil de las copias de seguridad físicas en muchas circunstancias, pero no son suficiente protección contra la pérdida de datos y sin respaldos físicos.
A menos que se especifique lo contrario, la copia de seguridad término tal como se utiliza en la copia de seguridad y la documentación de recuperación se refiere a una copia de seguridad física. Copia de seguridad de una base de datos es el acto de hacer una copia de seguridad física. El enfoque en la copia de seguridad y recuperación de documentación está casi exclusivamente en copias de seguridad físicas.
Mientras que varios problemas pueden detener el funcionamiento normal de una base de datos Oracle o afectar a las operaciones de base de datos de E / S, solamente la siguiente normalmente requiere la intervención del DBA y de recuperación de datos: un error de medios, errores de usuario, y los errores de aplicación. Otros fallos pueden requerir intervención DBA sin causar la pérdida de datos o que requieren la recuperación de copia de seguridad. Por ejemplo, es posible que tenga que reiniciar la base de datos tras un fallo de instancia o asignar más espacio de disco después de un fallo debido a la declaración de un archivo de datos completo.
Las Fallas de Medios
La falta de medios es un problema físico con un disco que provoca un fallo de una leer o escribir en un archivo de disco que se requiere para ejecutar la base de datos. Cualquier archivo de base de datos puede ser vulnerable a un fallo de comunicación. La técnica de recuperación adecuada después de un fallo de los medios de comunicación depende de los archivos afectados y el tipo de copia de seguridad disponible.
Un aspecto particularmente importante de la copia de seguridad y recuperación se está desarrollando una estrategia de recuperación ante desastres para proteger contra la pérdida de datos catastrófica, por ejemplo, la pérdida de toda una serie de bases de datos.
Errores de los Usuarios
Los errores del usuario cuando se producen, ya sea debido a un error en la lógica de la aplicación o un error manual, los datos en una base de datos se modifican o eliminan incorrectamente. Errores de usuario se estima que la mayor causa de inactividad de base de datos.
La pérdida de datos debido a un error del usuario puede ser localizada o generalizada. Un ejemplo de daño localizado está eliminando a la persona equivocada en la tabla empleados. Este tipo de lesiones requiere la detección y la reparación quirúrgica. Un ejemplo de un daño generalizado es un trabajo por lotes que borra las órdenes de la empresa para el mes en curso. En este caso, se requiere una acción drástica para evitar una extensa base de datos de tiempo de inactividad.
Mientras que la formación de usuarios y el manejo cuidadoso de los privilegios pueden prevenir la mayoría de los errores de usuario, su estrategia de copia de seguridad determina la gracia de recuperar los datos perdidos cuando un error del usuario que hace perder los datos.
Errores de Aplicación
A veces, un mal funcionamiento de software puede dañar los bloques de datos. En una corrupción física, que también se conoce como la corrupción los medios de comunicación, la base de datos no reconoce el bloque en absoluto: la suma de comprobación no es válida, el bloque contiene todos los ceros, o el encabezado y el pie de página del bloque no coinciden. Si el daño no es muy amplio, puede a menudo repara fácilmente con bloque de recuperación de medios.
Preservación de Datos
Conservación de datos se relaciona con la protección de datos, pero tiene un propósito diferente. Por ejemplo, puede que tenga que conservar una copia de una base de datos tal como existía al final de la cuarta parte del negocio. Esta copia de seguridad no es parte de la estrategia de recuperación de desastres. Los medios a los que estas copias de seguridad se escriben a menudo disponible después de la copia de seguridad. Usted puede enviar la cinta en almacenamiento incendio o enviar un disco duro portátil a un centro de pruebas. RMAN proporciona una manera conveniente para crear una copia de seguridad y eximirla de su política de retención de copia de seguridad. Este tipo de copia de seguridad se conoce como una copia de seguridad de archivo.
Transferencia de Datos
En algunas situaciones, es posible que tenga que tomar una copia de seguridad de una base de datos o base de datos de componentes y moverlo a otra ubicación. Por ejemplo, puede utilizar el Administrador de recuperación (RMAN) para crear una copia de base de datos, cree una copia de tabla que se puede importar en otra base de datos, o mover una base de datos completa de una plataforma a otra. Estas tareas no son, estrictamente hablando, parte de una estrategia de backup y recuperación, pero requieren el uso de copias de seguridad de bases de datos, por lo que pueden incluirse en las tareas de un administrador de copia de seguridad.
Oracle Backup y Recuperación de Soluciones
Al implementar una estrategia de backup y recuperación, dispone de las siguientes soluciones disponibles:
· Administrador de Recuperación (RMAN)
Recovery Manager está completamente integrado con la base de datos Oracle para llevar a cabo una serie de actividades de copia de seguridad y recuperación, incluyendo el mantenimiento de un repositorio de RMAN de datos históricos acerca de las copias de seguridad. Se puede acceder a RMAN través de la línea de comandos oa través de Oracle Enterprise Manager.
· Copia de Seguridad y Recuperación Gestionadas por el Usuario
En esta solución, realizar copias de seguridad y recuperación con una mezcla de comandos del sistema operativo host y SQL * Plus.
Recuperación de Comandos
Ustedes son responsables de determinar todos los aspectos de cuándo y cómo las copias de seguridad y la recuperación se hacen.
Estas soluciones están respaldadas por Oracle y se documentan, pero RMAN es la mejor solución para copia de seguridad y recuperación de bases de datos. RMAN proporciona una interfaz común para las tareas de copia de seguridad a través de diferentes sistemas operativos host, y ofrece varias técnicas de copia de seguridad que no están disponibles a través de métodos administrados por usuarios.
La mayor parte de este manual se centra en la copia de seguridad y recuperación de RMAN basado. Técnicas de copia de seguridad y recuperación gestionadas por el usuario se tratan en Realización de usuario-Managed Backup and Recovery. Las más destacables son los siguientes:
· Copias de Seguridades Incrementales
Una copia de seguridad incremental almacena sólo los bloques modificados desde la última copia de seguridad. Por lo tanto, proporcionan copias de seguridad más compacta y una recuperación más rápida, lo que reduce la necesidad de aplicar de rehacer en archivo de datos de recuperación de los medios de comunicación. Si se habilita el seguimiento de cambios de bloque, entonces usted puede mejorar el rendimiento al evitar escaneos completos de todos los archivos de datos de entrada. Utilice el comando Copia de seguridad incremental para realizar copias de seguridad incrementales.
· Bloquear los Medios de Recuperación
Usted puede reparar un archivo de datos con sólo un pequeño número de bloques de datos corruptos sin tomarlo fuera de línea o la restauración desde copia de seguridad. Utilice el comando BLOQUE RECOVER para realizar la recuperación del bloque de comunicación.
· Compresión Binaria
Un mecanismo de compresión binaria integrado en base de datos Oracle reduce el tamaño de las copias de seguridad.
· Copias de Seguridad Encriptadas
RMAN utiliza las capacidades de cifrado de copia de seguridad integrados en bases de datos Oracle para almacenar conjuntos de copia de seguridad en un formato codificado. Para crear copias de seguridad cifradas en el disco, la base de datos debe utilizar la opción de seguridad avanzada. Para crear copias de seguridad encriptadas directamente en cinta, RMAN debe utilizar la copia de seguridad de Oracle Secure interfaz SBT, pero no requiere la opción de seguridad avanzada.
· Duplicación de la Base de Datos Automatizada
Crea fácilmente una copia de su base de datos, el apoyo a diversas configuraciones de almacenamiento, incluida la duplicación directa entre las bases de datos de ASM.
· Conversión de Datos entre Plataformas
Ya sea que utilice RMAN o métodos administrados por usuarios, puede complementar las copias de seguridad físicas con copias de seguridad lógicas de objetos de esquema realizados con la utilidad Export Data Pump. Más tarde, puede utilizar Data Pump Import para volver a crear los datos después de la restauración y la recuperación. Copias de seguridad lógicas son en su mayoría más allá del alcance de la copia de seguridad y de recuperación de documentación.
4.3 Comandos de Activación para los Modos de Operación
Para ser uso de los diferentes comandos para un modo de operación debemos estar como administrador o asuma un rol que incluya el perfil de derechos Service Management.
Comando STARTUP
Para el arranque de una base de datos hay tres fases de arranque, para realizar estas fases podemos utilizar startup más un comando, las tres fases son las siguientes:
Fase de no Montaje: se leen los parámetros del sistema, se inician las estructuras de memoria y los procesos de segundo plano. La instancia se arranca sin asociarla a la base de datos. Normalmente se utiliza cuando se modifica o se necesita crear el archivo de control:
startup nomount ;
Fase de Montaje: se asocia la instancia con la base de datos. Se usa el archivo de parámetros para localizar los archivos de control, que contienen el nombre de los archivos de datos y los registros rehacer. Los archivos de datos y los registros de rehacer no están abiertos, así que no son accesibles por usuarios finales para tareas normales. Para realizar esta fase se pueden utilizar dos comandos:
startup mount;
alter database mount;
Fase de Apertura: se abren los archivos de datos y los registros rehacer. La base de datos queda disponible para las operaciones normales. Es necesario que existan registros rehacer de lo contrario si no hay registros usamos el comando resetlogs, que crea registros nuevos. Para esta fase se pueden usar dos comandos:
startup open;
alter database open;
Si es necesario utilizar resetlogs:
startup open resetlogs;
alter database open resetlogs;
startup restrict (sólo permite la conexión de usuarios con el privilegio restricted sesion).
startup force (hace shutdown abort y arranca la BD).
Comando SHUTDOWN
El comando SHUTDOWN lo utilizamos parar una base de datos la cual consiste en varias cláusulas.
Shutdown Normal: Este es el valor por defecto, durante el proceso de parada no admite nuevas conexiones y espera que las conexiones actuales finalicen. En el próximo arranque la base datos no requiere procedimientos de recuperación.
Shutdown Immediate: Se produce una parada inmediata de la base de datos, durante el proceso de parada no permite nuevas conexiones y las actuales la desconecta, las transacciones que no estén commit se hara roolback de ellas. En el próximo arranque la base datos no requiere procedimientos de recuperación.
Shutdown Transactional: Se produce una parada hasta que hayan terminado las transacciones activas, no admite nuevas conexiones y tampoco nuevas transacciones, una vez que las transacciones activas van terminando va desconectando a los usuarios. En el próximo arranque la base datos no requiere procedimientos de recuperación.
Shutdown Abort: Aborta todos los procesos de una base de datos, durante el proceso de parada no permite nuevas conexiones y las actuales la desconecta, las transacciones que no estén commit se hará roolback de ellas. En el próximo arranque la base datos puede requerir procedimientos de recuperación.
Comando Describe
Este comando permite conocer la estructura de una tabla, las columnas que la forman y su tipo y restricciones.
DESCRIBE f1;
Comando SHOW TABLES y SHOW CREATE TABLE
El comando SHOW TABLES muestra las tablas dentro de una base de datos y SHOW CREATE TABLES muestra la estructura de creación de la tabla.
Modificación
Para realizar una modificación utilizamos el comando ALTER TABLE. Para usar ALTER TABLE, necesita permisos ALTER, INSERT y CREATE para la tabla.
4.4.- Manejo de Índices
El índice de una base de datos es una estructura alternativa de los datos en una tabla. El propósito de los índices es acelerar el acceso a los datos mediante operaciones físicas más rápidas y efectivas. En pocas palabras, se mejoran las operaciones gracias a un aumento de la velocidad, permitiendo un rápido acceso a los registros de una tabla en una base de datos. Al aumentar drásticamente la velocidad de acceso, se suelen usar sobre aquellos campos sobre los cuáles se hacen búsquedas frecuentes.
4.4.1 Tipos de Índices
Resumen de Índices
Un índice es una estructura opcional, asociado con una mesa o tabla de clúster, que a veces puede acelerar el acceso de datos. Mediante la creación de un índice en una o varias columnas de una tabla, se obtiene la capacidad en algunos casos, para recuperar un pequeño conjunto de filas distribuidas al azar de la tabla. Los índices son una de las muchas formas de reducir el disco I / O.
Si una tabla de montón organizado no tiene índices, entonces la base de datos debe realizar un escaneo completo de tabla para encontrar un valor. Por ejemplo, sin un índice, una consulta de ubicación 2700 en la tabla hr.departments requiere la base de datos para buscar todas las filas de cada bloque de la tabla para este valor. Este enfoque no escala bien como datos de aumento de volúmenes.
Por analogía, supongamos que un gerente de Recursos Humanos tiene un estante de cajas de cartón. Las carpetas que contienen información de los empleados se insertan aleatoriamente en las cajas. La carpeta de empleado Whalen (ID 200) es de 10 carpetas desde el fondo de la caja 1, mientras que la carpeta para el rey (ID 100) se encuentra en la parte inferior del cuadro 3. Para localizar una carpeta, el gestor busca en cada carpeta en la casilla 1 de abajo hacia arriba, y luego se mueve de una casilla a otra hasta que se encuentra la carpeta. Para acelerar el acceso, el administrador puede crear un índice que enumera de forma secuencial todos los ID de empleado con su ubicación de la carpeta:
ID 100: Box 3, position 1 (bottom)
ID 101: Box 7, position 8
ID 200: Box 1, position 10
Del mismo modo, el administrador podría crear índices separados para los últimos nombres de los empleados, los ID de departamento, y así sucesivamente.
En general, considerar la creación de un índice en una columna en cualquiera de las siguientes situaciones:
· Las columnas indizadas se consultan con frecuencia y devuelven un pequeño porcentaje del número total de filas en la tabla.
· Existe una restricción de integridad referencial en la columna o columnas indexadas. El índice es un medio para evitar un bloqueo de tabla completa que de otro modo se requeriría si se actualiza la clave principal de la tabla principal, se funden en la tabla principal, o eliminar de la tabla primaria.
· Una restricción de clave única se coloca sobre la mesa y desea especificar manualmente el índice de todas las opciones sobre índices y.
Características de Indexación
Los índices son objetos de esquema que son lógica y físicamente independiente de los datos de los objetos con los que están asociados. Por lo tanto, un índice se puede quitar o creado sin afectar físicamente a la tabla para el índice.
Nota: Si se le cae un índice, las aplicaciones siguen funcionando. Sin embargo, el acceso de los datos previamente indexado puede ser más lento.
La ausencia o presencia de un índice no requiere un cambio en el texto de cualquier sentencia SQL. Un índice es una ruta de acceso rápido a una sola fila de datos. Sólo afecta a la velocidad de ejecución. Dado un valor de datos que se ha indexado, el índice apunta directamente a la ubicación de las filas que contienen ese valor.
La base de datos mantiene automáticamente y utiliza los índices después de su creación. La base de datos también refleja automáticamente los cambios en los datos, como agregar, actualizar y eliminar filas, en todos los índices pertinentes sin acciones adicionales requeridas por los usuarios. Rendimiento de recuperación de datos indexados permanece casi constante, incluso cuando se insertan filas. Sin embargo, la presencia de muchos índices en una tabla degrada el rendimiento DML porque la base de datos también debe actualizar los índices.
Los índices tienen las siguientes propiedades:
· Facilidad de Uso
Los índices son utilizables (por defecto) o inutilizable. Un índice inutilizables no se mantiene por las operaciones DML y es ignorado por el optimizador. Un índice inutilizable puede mejorar el rendimiento de las cargas a granel. En lugar de dejar un índice y luego volverlo a crear, puede hacer que el índice inservible y luego reconstruirlo. Índices inutilizables y las particiones de índice no consumen espacio. Cuando usted hace un índice utilizable no utilizable, la base de datos cae su segmento de índice.
· Visibilidad
Los índices son visibles (por defecto) o invisible. Un índice invisible se mantiene por las operaciones DML y no se utiliza de forma predeterminada por el optimizador. Cómo hacer una invisible índice es una alternativa a lo que es inutilizable o se caiga. Índices invisibles son especialmente útiles para probar la eliminación de un índice antes de dejarlo caer o mediante índices temporalmente sin afectar a la aplicación general.
Guía del Administrador para Aprender a Manejar los Índices
· Base de datos Oracle Performance Tuning Guide para aprender cómo ajustar los índices
Teclas y Columnas
Una clave es un conjunto de columnas o expresiones en las que se puede construir un índice. Aunque los términos se usan indistintamente, los índices y las claves son diferentes. Los índices son estructuras almacenados en la base de datos que los usuarios a administrar el uso de sentencias de SQL. Las claves son estrictamente un concepto lógico.
La siguiente sentencia crea un índice en la columna customer_id de la muestra oe.orders tabla:
CREATE INDEX ord_customer_ix ON orders (customer_id);
En la declaración anterior, la columna customer_id es la clave de índice. El índice en sí se llama ord_customer_ix.
Índices Compuestos
Un índice compuesto, también llamado índice concatenado, es un índice de varias columnas de una tabla. Las columnas de un índice compuesto que deben aparecer en el orden que tenga más sentido para las consultas que recuperar datos y no necesita ser adyacente en la tabla.
Los índices compuestos pueden acelerar la recuperación de datos para las instrucciones SELECT en la que el DONDE referencias cláusula totalidad o la parte principal de las columnas en el índice compuesto. Por lo tanto, el orden de las columnas utilizadas en la definición es importante. En general, las columnas de acceso más común van primero.
Por ejemplo, supongamos que una aplicación realiza consultas frecuentes a apellidos, job_id, y columnas de salario en la tabla empleados. También asumir que last_name tiene alta cardinalidad, lo que significa que el número de valores distintos que es grande en comparación con el número de filas de la tabla. Se crea un índice con el siguiente orden de las columnas:
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);
Las consultas que acceden a las tres columnas, sólo la columna last_name, o sólo el last_name y columnas job_id utilizan este índice. En este ejemplo, las consultas que no tienen acceso a la columna last_name no utilizan el índice.
Nota: En algunos casos, tales como cuando la columna principal tiene muy baja cardinalidad, la base de datos puede utilizar una búsqueda selectiva de este índice.
Múltiples índices pueden existir para la misma mesa, siempre y cuando la permutación de columnas difiere para cada índice. Puede crear varios índices que utilizan las mismas columnas si se especifica claramente diferentes permutaciones de las columnas. Por ejemplo, las siguientes sentencias SQL especifican permutaciones válidas:
CREATE INDEX employee_idx1 ON employees (last_name, job_id);
CREATE INDEX employee_idx2 ON employees (job_id, last_name);
Índices Únicos y no Únicos
Los índices pueden ser únicos o no únicos. Índices únicos garantizar que no hay dos filas de una tabla tienen valores duplicados en la columna de clave o columna. Por ejemplo, dos empleados no pueden tener el mismo ID de empleado. Por lo tanto, en un índice único, existe una ROWID para cada valor de datos. Los datos de los bloques de hojas se ordenan sólo por clave.
Índices no únicas permiten valores duplicados en la columna o columnas indexadas. Por ejemplo, la columna 'nombre de la tabla de empleados puede contener varios valores Mike. Para un índice no único, el ROWID se incluye en la clave de forma ordenada, por lo que los índices no únicos se ordenan por la clave de índice y ROWID (ascendente).
Oracle Database no filas de la tabla de índice en el que todas las columnas clave son nulas, a excepción de los índices de mapa de bits o cuando el valor de la columna clave de clúster es nulo.
Tipos de Índices
Base de Datos Oracle ofrece varias combinaciones de indexación, que proporcionan una funcionalidad complementaria sobre el rendimiento. Los índices se pueden clasificar de la siguiente manera:
· Los Índices de Árbol B
Estos índices son el tipo de índice estándar. Son excelentes para la clave principal y los índices altamente selectivos. Utilizado como índices concatenados, B-tree índice pueden recuperar los datos ordenados por las columnas de índice. Índices B-tree tienen los siguientes subtipos:
· Índice de Tablas Organizadas
Una tabla de índice-organizada difiere de un montón-organizado porque los datos es en sí mismo el índice.
En este tipo de índice, los bytes de la clave de índice se invierten, por ejemplo, 103 se almacena como 301. La inversión de bytes extiende inserta en el índice durante muchos bloques.
· Índices Descendentes
Este tipo de índice almacena los datos en una columna o columnas de concreto en orden descendente.
· Índices B-Tree de Racimo
Este tipo de índice se utiliza para indexar una clave de clúster tabla. En lugar de apuntar a una fila, los puntos clave para el bloque que contiene filas relacionadas con la clave de clúster.
· Mapa de Bits y los Índices Bitmap Join
En un índice de mapa de bits, una entrada de índice utiliza un mapa de bits para que apunte a varias filas. En cambio, los puntos de entrada de un índice B-tree en una sola fila. Un índice de combinación de mapa de bits es un índice de mapa de bits para la unión de dos o más tablas. Consulte "Indicadores de mapa de bits".
· Índices Basados en Funciones
Este tipo de índice incluye columnas que, o bien se transforman por una función, tales como la función UPPER, o incluidos en una expresión. Índices B-tree o mapa de bits puede ser basado en las funciones.
· Índices de Dominio de Aplicación
Este tipo de índice se crea por un usuario para los datos en un dominio específico de la aplicación. El índice físico no tiene que utilizar una estructura de índice tradicional y se puede almacenar ya sea en la base de datos Oracle como tablas o externamente como un archivo. Consulte "Indicadores de dominio de aplicación".
· Índices B-Tree
Árboles B, abreviatura de árboles balanceados, son el tipo más común de índice de base de datos. Un índice B-tree es una lista ordenada de valores dividida en rangos. Mediante la asociación de una tecla con una fila o rango de filas, los árboles B proporcionan un excelente rendimiento de la recuperación para una amplia gama de consultas, incluyendo coincidencia exacta y búsquedas por rango.
La figura 3-1 ilustra la estructura de un índice B-tree. El ejemplo muestra un índice en la columna department_id, que es una columna de clave externa en la tabla empleados.
4.4.2 Reorganización de Índices.
Un factor clave para conseguir una E/S de disco mínima para todas las consultas de bases de datos es asegurarse de que se creen y se mantengan buenos índices. Una vez creados los índices, se debe procurar mantenerlos para asegurarse que sigan trabajando en forma óptima. A medida que se agregan, modifican o borran datos se produce fragmentación. Esta fragmentación puede ser buena o mala para el rendimiento del sistema, dependiendo de las necesidades del trabajo de la base de datos.
Fragmentación de los Índices
La fragmentación es consecuencia de los procesos de modificación de los datos (instrucciones INSERT, UPDATE y DELETE) efectuados en la tabla y en los índices definidos en la tabla. Como dichas modificaciones no suelen estar distribuidas de forma equilibrada entre las filas de la tabla y los índices, el llenado de cada página puede variar con el paso del tiempo. Para las consultas que recorren parcial o totalmente los índices de una tabla, este tipo de fragmentación puede producir lecturas de páginas adicionales. Esto impide el recorrido paralelo de los datos. Existen dos tipos de fragmentación:
Interna: Fragmentación dentro de páginas individuales de datos e índices con espacios libres que generan la necesidad de más operaciones de E/S y más memoria para su lectura. Este hecho disminuye el rendimiento en ambientes de lectura, pero en algunos casos puede beneficiar las inserciones, que no requieren una división de páginas con tanta frecuencia.
Externa: Cuando el orden lógico de las páginas no es correcto, porque las páginas no son contiguas. El acceso a los datos es mucho más lento por la necesidad de búsqueda de los datos.
La fragmentación de índices se puede reparar reorganizando un índice o reconstruyéndolo. Para los índices fraccionados que fueron construidos en una estructura partida se puede usar cualquiera de estos métodos o bien en un índice completo o bien en un único fragmento del índice.
Detección de Fragmentación
El primer paso para decidir qué método de desfragmentación se va a utilizar consiste en analizar el índice para determinar el nivel de fragmentación. Si se usa la función del sistema sys.dm_db_index_physical_stats, se puede detectar la fragmentación de los índices de la base de datos thuban-homologada.
SELECT DISTINCT
A.INDEX_ID 'IDIndice';
sys.TABLES.name 'Tabla',
b.name 'Indice',
avg_fragmentation_in_percentr '% Fragmentación',
fragment_count 'Cantidad de Fragmentos',
avg_fragment_size_in_pages 'Promedio de fragmentos por página',
FROM
sys.dm_db_index_physical_stats (
DB_ID ()N'thuban-himologada'),
OBJECT_ID (N'dbo.*'),
NULL,
NULL,
NULL) AS a JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id,
sys.TABLES
WHERE
sys.TABLES.object_id = b.object_id
ORDER BY
avg_fragmentation_in_percent DESC
La grilla de resultados emitida por la anterior sentencia incluye las siguientes columnas:

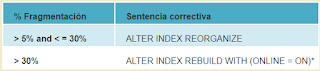
Una vez que se toma conciencia del nivel de fragmentación, se debe utilizar la tabla a continuación para determinar el mejor método para su corrección.

La reconstrucción del índice puede ejecutarse tanto en línea como fuera de línea. La reorganización de los índices debe ejecutarse siempre en línea. Para adquirir una disponibilidad similar a la de la opción de reorganización, los índices deben ser reconstruidos en línea.
Estos valores proveen una estricta guía para determinar el punto en el que se debe cambiar de ALTER INDEX REORGANIZE a ALTER INDEX REBUILD.
Los niveles muy bajos de fragmentación (menores que el 5 por ciento) no deben ser corregidos por ninguno de estos comandos porque el beneficio de la remoción de una cantidad tan pequeña de fragmentación es casi siempre superado ampliamente por el costo de reorganización o reconstrucción de índices.
Reorganización de Índices
Para reorganizar uno o más índices se debe usar la sentencia ALTER INDEX con la cláusula REORGANIZE. Por ejemplo:
ALTER INDEX PK_LOGS ON THUBAN_LOGS REORGANIZE
El proceso de reorganización de índices se realiza siempre en línea y el consumo de recursos es bajo por lo que no mantiene bloqueos por mucho tiempo.
4.4.3 Reconstrucción de Índices
Es importante periódicamente examinar y determinar qué índices son susceptibles de ser reconstruidos. Cuando un índice está descompensado puede ser porque algunas partes de éste han sido accedidas con mayor frecuencia que otras. Como resultado de este suceso podemos obtener problemas de contención de disco o cuellos de botella en el sistema. Normalmente reconstruimos un índice con el comando ALTER INDEX.
Es importante tener actualizadas las estadísticas de la base de datos. Para saber si las estadísticas se están lanzando correctamente podemos hacer una consulta sobre la tabla dba_indexes y ver el campo last_analyzed para observar cuando se ejecutaron sobre ese índice las estadísticas.
Blevel (branch level) es parte del formato del B-tree del índice e indica el número de veces que Oracle ha tenido que reducir la búsqueda en ese índice. Si este valor está por encima de 4 el índice deberá de ser reconstruido.
ALTER INDEX <index_name> REBUILD;
Para reconstruir una partición de un índice podríamos hacer los siguiente:
ALTER INDEX <index_name> REBUILD PARTITION <nb_partition> NOLOGGING;
Nota: En algunos casos cuando alguno de los índices tiene algún tipo de corrupción no es posible reconstruirlo. La solución en este caso es borrar el índice y recrearlo.
lunes, 20 de mayo de 2019
Unidad 3: Configuración y Administración del Espacio en Disco
3.1 Estructuras Lógicas de Almacenamiento
Para la gestión del almacenamiento de una base de datos existen 4 conceptos bien definidos que deben ser conocidos para poder comprender la forma en la que se almacenan los datos. Vamos a ver la diferencia entre bloque, extensión, segmento y espacio de tablas.
Bloques: Se tratan de la unidad más pequeña. Generalmente debe múltiple del tamaño de bloque del sistema operativo, ya que es la unidad mínima que va a pedir Oracle al sistema operativo. Si no fuera múltiple del bloque del sistema se añadiría un trabajo extra ya que el sistema debería obtener más datos de los estrictamente necesarios. Se especifica mediante DB_BLOCK_SIZE
Extensiones: Se forma con uno o más bloques. Cuando se aumenta tamaño de un objeto se usa una extensión para incrementar el espacio.
Segmentos: Grupo de extensiones que forman un objeto de la base de datos, como por ejemplo una tabla o un índice.
Espacio de Tablas: Formado por uno o más datafiles, cada datafile solo puede pertenecer a un determinado tablespace
En general, el almacenamiento de los objetos de la base de datos (tablas e índices fundamentalmente) no se realiza sobre el archivo o archivos físicos de la base de datos, sino que se hace a través de estructuras lógicas de almacenamiento que tienen por debajo a esos archivos físicos, y que independizan por tanto las sentencias de creación de objetos de las estructuras físicas de almacenamiento. Esto es útil porque permite que a esos "espacios de objetos " les sean asociados nuevos dispositivos físicos (es decir, más espacio en disco) de forma dinámica cuando la base de datos crece de tamaño más de lo previsto. Posibilita además otra serie de operaciones como las siguientes:
· Asignar cuotas específicas de espacio a usuarios de la base de datos.
· Controlar la disponibilidad de los datos de la base de datos, poniendo fuera de uso alguno de esos espacios de tablas individualmente.
· Realizar copias de seguridad o recuperaciones parciales de la base de datos.
· Reservar espacio para almacenamiento de datos de forma cooperativa entre distintos dispositivos.
El administrador de la base de datos puede crear o borrar nuevos espacios lógicos de objetos, añadir o eliminar ficheros físicos de soporte, utilizados como espacio temporal de trabajo, definir parámetros de almacenamiento para objetos destinados a ese espacio de datos, todos los gestores relacionales que venimos introduciendo como ejemplos siguen esta filosofía. En el caso de Oracle, sobre los ficheros físicos de datos (datafiles) se definen los tablespaces. Por lo tanto, una base de datos Oracle se compone lógicamente de tablespaces, y físicamente de datafiles. Su creación es sencilla, con la sentencia GREAT'', TABLESPACE: CREATE TABLESPACE usuarios DATAFILE `datal.ora' SIZE 50M
También es sencillo ampliar el espacio destinado a un tablespace utilizando el comando ALTER TABLESPACE:
ALTER TABLESPACE usuarios ADD DATAFILE 'data2.ora' SIZE 25M
Para hacer más grande una base de datos, las opciones disponibles son tres:

Cada base de datos contiene un tablespace llamado SYSTEM que es creado automáticamente al crear la base de datos. Contiene las tablas del diccionario de datos para la base de datos en cuestión. Es recomendable no cargar datos de usuario en SYSTEM, para dejarlos como espacio de objetos del sistema.
Si además los datos de usuario están en tablespaces sitos en otros dispositivos, el rendimiento mejorará porque las tablas del diccionario de datos se acceden frecuentemente y por lo tanto son un cuello de botella potencial desde el punto de vista del acceso a disco. A la hora de estimar el espacio necesario para cl tablespace sys-nsm hay que tener en cuenta que las unidades de programación PL-SQL (entorno de programación SQL proporcionado por Oracle) almacenadas en la base de datos (procedimientos, paquetes, disparos y funciones) almacenan sus datos en SYSTEM.
3.1.1 Definición de Almacenamiento de Bases de Datos
Las bases de datos suelen ser creadas para almacenar grandes cantidades de datos de forma permanente. Por lo general, los datos almacenados en éstas suelen ser consultados y actualizados constantemente.
La mayoría de las bases de datos se almacenan en las llamadas memorias secundarias, especialmente discos duros, aunque, en principio, pueden emplearse también discos ópticos, memorias flash, etc.
Las razones por las cuales las bases de datos se almacenan en memorias secundarias son:
· En general, las bases de datos son demasiado grandes para entrar en la memoria primaria.
· La memoria secundaria suele ser más barata que la memoria primaria (aunque esta última tiene mayor velocidad).
· La memoria secundaria es más útil para el almacenamiento de datos permanente, puesto que la memoria primaria es volátil.
3.1.2.- Definición y Creación del Espacio Asignado para cada Base de Datos
Las bases de datos se almacenan en ficheros o archivos. Existen diferentes formas de organizaciones primarias de archivos que determinan la forma en que los registros de un archivo se colocan físicamente en el disco y, por lo tanto, cómo se accede a éstos.
Las distintas formas de organizaciones primarias de archivos son:
· Archivos de Montículos (o no Ordenados): esta técnica coloca los registros en el disco sin un orden específico, añadiendo nuevos registros al final del archivo.
· Archivos Ordenados (o Secuenciales): mantiene el orden de los registros con respecto a algún valor de algún campo (clave de ordenación).
· Archivos de Direccionamiento Calculado: utilizan una función de direccionamiento calculado aplicada a un campo específico para determinar la colocación de los registros en disco.
· Árboles B: se vale de la estructura de árbol para las colocaciones de registros.
· Organización Secundaria o Estructura de Acceso Auxiliar: Estas permiten que los accesos a los registros de un archivo basado en campos alternativos, sean más eficientes que los que han sido utilizados para la organización primaria de archivos.
El DBMS asigna espacio de almacenamiento a las bases de datos cuando los usuarios introducen create database o alter database. El primero de los comandos puede especificar uno o más dispositivos de base de datos, junto con la cantidad de espacio en cada uno de ellos que será asignado a la nueva base de datos.
Si se utiliza la palabra clave default o se omite completamente la cláusula on, el DBMS pone la base de datos en uno o más de los dispositivos predeterminados de base de datos especificados en master.sysdevices.
Para especificar un tamaño (por ejemplo, 4MB) para una base de datos que se va a almacenar en una ubicación predeterminada, se utiliza: on default = size de esta forma:
create database newpubs on default = 4
3.1.3.- Bitácoras
Son estructuras ampliamente utilizadas para grabar las modificaciones de la base de datos.
Cada registro de la bitácora escribe una única escritura de base de datos y tiene lo siguiente:
· Nombre de la Transacción: Nombre de la transacción que realizó la operación de escritura.
· Nombre del Dato: El nombre único del dato escrito.
· Valor Antiguo: El valor del dato antes de la escritura.
· Valor Nuevo: El valor que tendrá el dato después de la escritura.
Es fundamental que siempre se cree un registro en la bitácora cuando se realice una escritura antes de que se modifique la base de datos.
También tenemos la posibilidad de deshacer una modificación que ya se ha escrito en la base de datos, esto se realizará usando el campo del valor antiguo de los registros de la bitácora.
Los registros de la bitácora deben residir en memoria estable como resultado el volumen de datos en la bitácora puede ser exageradamente grande.
La instrucción en MySQL para crear una bitácora en .txt se crea antes de acceder a la base de datos con la instrucción:
"xampp>mysql>bin>mysql -hlocalhost -uroot --tee=C:bitacora.txt"
La bitácora debe registrar todos los movimientos (insertar, eliminar y modificar) que se realicen en las tablas de la base de datos. Para lograr lo anterior es necesario crear un trigger para que se ejecute después de la operación de insertar, otro para después de eliminar y el último para después de modificar para cada una de las 3 tablas de la base de datos.
3.1.4.- Particiones
Cuando alguna de las tablas de una base de datos llega a crecer tanto que el rendimiento empieza a ser un problema, es hora de empezar a conocer algo sobre optimización. Una característica de MySQL son las particiones.
Particionar tablas en MySQL nos permite rotar la información de nuestras tablas en diferentes particiones, consiguiendo así realizar consultas más rápidas y recuperar espacio en disco al borrar los registros. El uso más común de particionado es según la fecha.
Para ver si nuestra base de datos soporta particionado simplemente ejecutamos:
SHOW VARIABLES LIKE '%partition%';
Se puede particionar una tabla de 5 maneras diferentes:
· Por Rango: para construir las particiones se especifican rangos de valores.
ALTER TABLE contratos
PARTITION BY RANGE (YEAR (fechaInicio)) (
PARTITION partDecada80 VALUES LESS THAN (1990),
PARTITION partDecada90 VALUES LESS THAN (2000),
PARTITION partDecada00 VALUES LESS THAN (2010),
PARTITION partDefault VALUES LESS THAN MAXVALUE
);
La última partición (partDefault) tendrá todos los registros que no entren en las particiones anteriores. De esta manera nos aseguramos que la información nunca dejará de insertarse en la tabla.
· Por Listas: para construir nuestras particiones especificamos listas de valores concretos.
ALTER TABLE contratos
PARTITION BY LIST (YEAR (fechaInicio)) (
PARTITION partDecada80 VALUES IN (1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989),
PARTITION partDecada90 VALUES IN (1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999),
PARTITION partDecada00 VALUES IN (2000, 2001, 2002, 2003, 2004, 2005, 2006,
2007, 2008, 2009),
PARTITION partDecada10 VALUES IN (2010, 2011, 2012, 2013, 2014, 2015, 2016,
2017, 2018, 2019)
);
· Por Hash: MySQL se encarga de distribuir las tuplas automáticamente usando una operación de módulo. Sólo hay que pasarle una columna o expresión que resulte en un entero (el hash) y el número de particiones que queramos crear.
ALTER TABLE contratos
PARTITION BY HASH (YEAR (fechaInicio))
PARTITIONS 7;
· Por Clave: similar a la partición por hash, pero en este caso no necesitamos pasarle un entero; MySQL utilizará su propia función de hash para generarlo. Si no se indica ninguna columna a partir de la que generar el hash, se utiliza la clave primaria por defecto.
ALTER TABLE contratos
PARTITION BY KEY ()
PARTITIONS 7;
· Compuesta: podemos combinar los distintos métodos de particionado y crear particiones de particiones
Borrar Particiones
Lo bueno de trabajar con particiones es que podemos borrar rápidamente registros sin tener que recorrer toda la tabla e inmediatamente recuperar el espacio en disco utilizado por la tabla.
Por ejemplo si queremos borrar la partición más antigua simplemente ejecutamos:
ALTER TABLE reports DROP PARTITION p201111;
Añadir particiones
En el ejemplo anterior las 2 últimas particiones creadas han sido:
PARTITION p201205 VALUES LESS THAN (TO_DAYS ("2012-06-01")),
PARTITION pDefault VALUES LESS THAN MAXVALUE
El problema es que todos los INSERT que se hagan después de mayo de 2012 se insertarán en pDefault. La solución sería añadir particiones nuevas para cubrir los próximos meses:
ALTER TABLE reports REORGANIZE PARTITION pDefault INTO (
PARTITION p201206 VALUES LESS THAN (TO_DAYS ("2012-07-01")),
PARTITION pDefault VALUES LESS THAN MAXVALUE);
En el caso que no tuviéramos una partición del tipo pDefault simplemente ejecutamos:
ALTER TABLE reports ADD PARTITION (PARTITION p201206 VALUES LESS THAN (TO_DAYS ("2012-07-01")));
Consultar Particiones
Para consultar información de particiones creadas en una tabla así como también los registros que contiene cada una ejecutamos:
SELECT PARTITION_NAME, TABLE_ROWS FROM information_schema.PARTITIONS WHERE TABLE_NAME='reports';
3.1.5.- Espacios Privados
Un “espacio privado” permite que los administradores y redactores gestionen el conjunto de datos del sitio. Algunas bases de datos tienen estos espacios privados llamados comúnmente paneles de control, que son formularios que aparecen al abrir la base de datos.
Los paneles de control sirven de "puerta principal" o "recibidor" de una base de datos en el sentido de que dirigen a las personas hacia determinadas tareas, como introducir o buscar datos. Sirven también para mantener alejados a los usuarios de las tablas que contienen los datos en tiempo real.
Cuando se recibe una base de datos, se averiguar cómo están estructurados los datos, revisar de manera general el panel de control. Puede ofrecer algún indicio sobre las tareas que el diseñador de la base de datos consideró que realizarían los usuarios habitualmente con los datos.
3.1.6.- Espacios para Objetos
Los DBMS se basan en archivos para almacenar datos, y estos archivos, o conjuntos de datos, residen en medios de almacenamiento, o dispositivos. Una buena parte del trabajo del DBA implicará la planificación para el almacenamiento real de la base de datos.
El rendimiento de la base de datos depende de la entrada y salida a disco. La cantidad de datos almacenados es mayor que nunca antes, y los datos son almacenados por más tiempo.
Algunos DBMS permiten al tamaño de los archivos temporales de expandirse y contraerse de forma automática. Dependiendo del tipo y la naturaleza de las operaciones de base de datos en proceso, esta fluctuación puede provocar picos de uso del disco.
Hay muchos problemas de almacenamiento que deben ser resueltos antes de que un DBA pueda crear una base de datos. Uno de los temas más importantes es la cantidad de espacio para permitir la base de datos.
El cálculo espacial debe tener en cuenta no sólo tablas, índices, sino también, y dependiendo del DBMS, el registro de transacciones. Cada una de estas entidades probablemente requerirá un archivo separado o conjunto de datos, para el almacenamiento persistente.
El DBA debe separar en diferentes discos a los archivos para:
· Mejorar el rendimiento
· Separar índices de datos
· Aislar los logros en otro disco
3.2 Segmentos
Los datos en la BD son almacenados físicamente en bloques Oracle: la mínima unidad de espacio físico, y es un múltiplo del bloque del SO (2 Kb usualmente). El tamaño del bloque Oracle se fija por el parámetro DB_BLOCK_SIZE del fichero init.ora. Un tamaño grande de bloque mejora la eficiencia del cache de E/S, pero el tamaño de la SGA aumentará para contener los mismos DB_BLOCK_BUFFERS, lo que significa un problema de memoria.
Una serie de bloques contiguos es una extensión, que es una unidad lógica de almacenamiento. Una serie de extensiones es un segmento. Cuando un objeto es creado, se reserva una extensión en su segmento. Cuando el objeto crezca, necesitará más espacio y se reservarán más extensiones.
Cada segmento tiene un conjunto de parámetros de almacenamiento que controla su crecimiento:
initial: tamaño de la extensión inicial (10k).
next: tamaño de la siguiente extensión a asignar (10k).
minextents: número de extensiones asignadas en el momento de la creación del segmento (1).
maxextents: número máximo de extensiones (99).
pctincrease: Porcentaje en el que crecerá la siguiente extensión antes de que se asigne, en relación con la última extensión utilizada (50).
pctfree: porcentaje de espacio libre para actualizaciones de filas que se reserva dentro de cada bloque asignado al segmento (10).
pctused: porcentaje de utilización del bloque por debajo del cual Oracle considera que un bloque puede ser utilizado para insertar filas nuevas en él.
tablespace: nombre del espacio de tablas donde se creará el segmento.
Cuando se diseña una BD se ha de tener mucho cuidado a la hora de dimensionar la BD y prever el crecimiento de las tablas. A continuación se hacen algunas consideraciones sobre la gestión del espacio para los diferentes segmentos.
Segmentos de Datos
El espacio del diccionario de datos se suele mantener más o menos constante, aunque es crítico que tenga suficiente espacio para crecer en el espacio de tablas SYSTEM. Así, hay que tener cuidado de colocar las tablas de usuario, los índices, segmentos temporales y los segmentos de rollback en otros espacios de tablas.
Además, es recomendable que el espacio de tablas SYSTEM esté al 50% o 75% de su espacio disponible. Finalmente, asegurarse que los usuarios no tienen privilegios de escritura en el espacio de tablas SYSTEM.
Las tablas crecen proporcionalmente con el número de filas, ya que se puede suponer que la longitud de las filas es constante.
Segmentos de Índice
Los índices crecen en tamaño en mayor proporción que las tablas asociadas si los datos en la tabla son modificados frecuentemente. La gestión del espacio es mejor si se mantienen los índices de tablas grandes en espacios de tablas separados.
Segmentos de Rollback
Los segmentos de rollback almacenan la imagen anterior a una modificación de un bloque. La información en el segmento de rollback se utiliza para asegurar la consistencia en lectura, el rollback (el valor en el segmento de rollback se copia en el bloque de datos) y la recuperación.
Es importante comprender cuál es el contenido de un segmento de rollback. No almacenan el bloque de datos modificado entero, sólo la imagen previa de la fila o filas modificadas. La información del segmento de roolback consiste en varias entradas llamadas undo. Por ejemplo, si se inserta una fila en una tabla, el undo necesitará sólo el rowid de la fila insertada, ya que para volver atrás la insercion sólo hay que realizar un delete. En las operación de actualización, se almacenará el valor antiguo de las columnas modificadas. El segmento de rollback asegura que la información undo se guardan durante la vida de la transacción.
Un segmento de rollback como cualquier otro segmento consiste en una serie de extensiones. Sin embargo, la mayor diferencia entre un segmento de datos y otro rollback es que en este último las extensiones se utilizan de manera circular. Así, habrá que tener cuidado a la hora de fijar el tamaño del segmento de rollback para que la cabeza no pille a la cola.
Segmentos Temporales
Los segmentos temporales se crean cuando se efectuan las siguientes operaciones:
Create Index
Select con distinct, order by, union, intersect y minus.
uniones no indexadas.
Ciertas subconsultas correlacionadas.
Si las tablas a ordenar son pequeñas la ordenación se realiza en memoria principal, pero si la tabla es grande se realiza en disco. El parámetro SORT_AREA_SIZE determina el lugar donde se hace la ordenación. Incrementándole se reduce la creación de segmentos temporales.
3.3 Definición de Memoria Compartida
Un servidor Oracle es un sistema que permite administrar bases de datos y que ofrece un medio de gestión de información abierto, completo e integrado.
Un servidor Oracle está constituido de una instancia y una base de datos.
Instancia de Oracle
Una instancia de Oracle permite acceder a la base de datos Oracle y permite abrir únicamente una sola base de datos.
La instancia de Oracle está compuesta de:
Procesos en segundo plano que administran y aplican las relaciones entre las estructuras físicas y las estructuras de memoria. Existen dos categorías:
· Procesos en Segundo Plano Obligatorios: DBWN, PMON, CKPT, LGWR, SMON
· Procesos en Segundo Plano Facultativos: ARCn, LMDn, RECO, CJQ0, LMON, Snnn, Dnnn, Pnnn, LCKn, QMNn
Estructuras de Memoria: compuestas básicamente de dos áreas de memoria: el área de memoria asignada a la SGA (System Global Area): asignada al inicio de la instancia y representa un componente fundamental de una instancia de Oracle.
Está compuesta de varias áreas de memoria:
Área de memoria compartida
Buffer caché de la base de datos
Log buffer
Así como otras estructuras para la gestión de bloqueos externos (lock), internos (match), datos estadísticos, etc.
Eventualmente también es posible configurar al nivel de la SGA
Área de memoria LARGE POOL
Área de memoria Java
Área de Memoria Asignada a la PGA (Program Global Area): Ésta es asignada al inicio del proceso de servidor. Es reservada a cada proceso de usuario que se conecte a la base de datos Oracle y liberada al final del proceso.
El Proceso de Usuario: Es el programa que solicita una interacción con la base de datos iniciando una conexión. Se comunica únicamente con el proceso de servidor correspondiente.
El Proceso de Servidor
Representa el programa que entra directamente en interacción con el servidor Oracle. Responde a todas las peticiones y envía los resultados. Puede estar dedicado a un servidor cliente o compartido por varios.
3.4 Definición de Múltiples Instancias de un DBMS
Cuando comenzamos a trabajar con Oracle una de las primeras cosas que aprendemos es a diferenciar entre estos conceptos: base de datos, instancia e instancia de base de datos.
Una instancia es el conjunto de procesos que se ejecutan en el servidor así como la memoria que comparten para ello.
Cuando se habla de base de datos, nos referimos a los archivos físicos que componen nuestra base de datos.
Si queremos referirnos a los procesos que se ejecutan en memoria como a los archivos de base de datos tendremos que utilizar el término instancia de base de datos.
La instancia en Oracle describe varios procesos residentes en la memoria del computador(es) y un área de memoria compartida por aquellos procesos. En arquitecturas de bases de datos tales como, Microsoft SQL Server e IBM BD2, la palabra instancia indica una colección de bases de datos que comparten recursos de memoria en común, o sea, la relación entre instancia y bases de datos es 1 a N. Pero la relación entre la instancia de Oracle y la base de datos es 1 a 1 o n a 1. Cuando hay una relación N a 1, la configuración es llamada RAC (Real Application CLuster), donde la base de datos reside en discos compartidos y las instancias en múltiples computadores anexados a la base de datos.
La instancia de Oracle es el motor que procesa los requerimientos de datos desde la base de datos. Está compuesta por procesos en primer plano, en segundo plano y un área de memoria compartida (SGA).

Una instancia de Oracle es un conjunto de estructuras de memoria que están asociadas con los archivos de datos (datafiles) en una máquina. Una base de datos es una colección de archivos físicos.
Instancia de Oracle
La integran los procesos 'background' y la SGA. Abre una y sólo una BDO, y permite acceder a ella.
Nota: con Oracle Real Application Cluster (RAC), más de una instancia usarán la misma BD.
En la máquina donde reside el servidor Oracle, la variable ORACLE_SID identifica a la instancia con la que estamos trabajando.
Vistas
V$DATABASE (Base de datos).
V$INSTANCE (Instancia).
V$SGA (SGA).
V$SGAINFO (Gestión dinámica de la SGA).
V$SGASTAT (SGA detallada).
V$BUFFER_POOL (Buffers en la caché de datos)
V$SQLAREA (Sentencias SQL).
V$PROCESS (Procesos).
V$BGPROCESS (Procesos background).
V$DATAFILE (Ficheros de datos de la BD).
V$CONTROLFILE (Ficheros de control de la BD).
V$LOGFILE (Ficheros redo log de la BD).
DBA_TABLESPACES (Tablespaces de la BD).
DBA_SEGMENTS (Segmentos que hay en los tablespaces).
DBA_EXTENTS (Extensiones que componen los segmentos).
DBA_USERS (Usuarios de la BD).
Oracle RAC(Real Application CLuster).
En un Rac de Oracle, múltiples instancias permiten el acceso a una única Base de datos. En un RAC las instancias corren en múltiples Nodos (servidores), y acceden a un conjunto común de datafiles que comprender a una 'Única' Base de datos."
En contraste, en un ambiente de una única instancia, una base de datos Oracle es usada por sólo UNA Instancia corriendo en el servidor. Por lo Tanto, los usuarios accediendo a la base de datos pueden conectarse a ésta, sólo a través de ese 'Único' servidor.
En un Oracle RAC, una base de datos puede ser montada por más de una instancia, y en cualquier punto, una instancia será parte de sólo una Base de datos. El almacén no volátil para archivos de datos que comprende la Base de datos es igualmente disponible a todos los nodos, para el acceso de lectura y escritura. De lo anterior se desprende que un RAC de Oracle necesita coordinar y regular el acceso “simultaneo” a los datos desde múltiples servidores (nodos), por ende, debe existir una red privada que sea eficiente, confiable y de alta rapidez, entre los nodos del clúster para enviar y recibir datos
Crear Instancias MySQL
Tener dos instancias o más tiene entre otras las siguientes justificaciones. Una se dedicará a desarrollo, para hacer las modificaciones y pruebas necesarias y otra al de producción.
Proceso
Copiar la carpeta data que se encuentra en nuestro caso en c:\MySQL, como data2

Copiar y pegar la configuración de MySQL. Es decir, del archivo my.ini (en linux my.cnf) generamos una copia que podría llamarse my2.ini.

Ahora con cuidado editamos my2.ini, procure no tocar my,ini a menos que este seguro de lo que hace.
Iniciamos configurando el puerto por donde escuchara MySQL la segunda instancia y la ruta de datos el archivo de datos.

Iniciar Instancia desde Consola
Desde la consola de ms-dos en modo administrador. [Tecla Win] + [X] y damos clic en Símbolo de Sistema (Administrador). Ahora introduzca desde la línea de comandos:
cd /MySQL/MySQL Server 5.6/bin
mysqld --defaults-file=my2.ini --explicit_defaults_for_timestamp = TRUE
mysql -u root -port 3307 -p

Establecer la Instancia como Servicio
Procederemos a instalar la nueva instancia como servicio. Desde la consola de ms-dos en modo administrador. En windows 8 pulse la [Tecla Win] + [X] y damos clic en Símbolo de Sistema (Administrador):

Para la gestión del almacenamiento de una base de datos existen 4 conceptos bien definidos que deben ser conocidos para poder comprender la forma en la que se almacenan los datos. Vamos a ver la diferencia entre bloque, extensión, segmento y espacio de tablas.
Bloques: Se tratan de la unidad más pequeña. Generalmente debe múltiple del tamaño de bloque del sistema operativo, ya que es la unidad mínima que va a pedir Oracle al sistema operativo. Si no fuera múltiple del bloque del sistema se añadiría un trabajo extra ya que el sistema debería obtener más datos de los estrictamente necesarios. Se especifica mediante DB_BLOCK_SIZE
Extensiones: Se forma con uno o más bloques. Cuando se aumenta tamaño de un objeto se usa una extensión para incrementar el espacio.
Segmentos: Grupo de extensiones que forman un objeto de la base de datos, como por ejemplo una tabla o un índice.
Espacio de Tablas: Formado por uno o más datafiles, cada datafile solo puede pertenecer a un determinado tablespace
En general, el almacenamiento de los objetos de la base de datos (tablas e índices fundamentalmente) no se realiza sobre el archivo o archivos físicos de la base de datos, sino que se hace a través de estructuras lógicas de almacenamiento que tienen por debajo a esos archivos físicos, y que independizan por tanto las sentencias de creación de objetos de las estructuras físicas de almacenamiento. Esto es útil porque permite que a esos "espacios de objetos " les sean asociados nuevos dispositivos físicos (es decir, más espacio en disco) de forma dinámica cuando la base de datos crece de tamaño más de lo previsto. Posibilita además otra serie de operaciones como las siguientes:
· Asignar cuotas específicas de espacio a usuarios de la base de datos.
· Controlar la disponibilidad de los datos de la base de datos, poniendo fuera de uso alguno de esos espacios de tablas individualmente.
· Realizar copias de seguridad o recuperaciones parciales de la base de datos.
· Reservar espacio para almacenamiento de datos de forma cooperativa entre distintos dispositivos.
El administrador de la base de datos puede crear o borrar nuevos espacios lógicos de objetos, añadir o eliminar ficheros físicos de soporte, utilizados como espacio temporal de trabajo, definir parámetros de almacenamiento para objetos destinados a ese espacio de datos, todos los gestores relacionales que venimos introduciendo como ejemplos siguen esta filosofía. En el caso de Oracle, sobre los ficheros físicos de datos (datafiles) se definen los tablespaces. Por lo tanto, una base de datos Oracle se compone lógicamente de tablespaces, y físicamente de datafiles. Su creación es sencilla, con la sentencia GREAT'', TABLESPACE: CREATE TABLESPACE usuarios DATAFILE `datal.ora' SIZE 50M
También es sencillo ampliar el espacio destinado a un tablespace utilizando el comando ALTER TABLESPACE:
ALTER TABLESPACE usuarios ADD DATAFILE 'data2.ora' SIZE 25M
Para hacer más grande una base de datos, las opciones disponibles son tres:
Cada base de datos contiene un tablespace llamado SYSTEM que es creado automáticamente al crear la base de datos. Contiene las tablas del diccionario de datos para la base de datos en cuestión. Es recomendable no cargar datos de usuario en SYSTEM, para dejarlos como espacio de objetos del sistema.
Si además los datos de usuario están en tablespaces sitos en otros dispositivos, el rendimiento mejorará porque las tablas del diccionario de datos se acceden frecuentemente y por lo tanto son un cuello de botella potencial desde el punto de vista del acceso a disco. A la hora de estimar el espacio necesario para cl tablespace sys-nsm hay que tener en cuenta que las unidades de programación PL-SQL (entorno de programación SQL proporcionado por Oracle) almacenadas en la base de datos (procedimientos, paquetes, disparos y funciones) almacenan sus datos en SYSTEM.
3.1.1 Definición de Almacenamiento de Bases de Datos
Las bases de datos suelen ser creadas para almacenar grandes cantidades de datos de forma permanente. Por lo general, los datos almacenados en éstas suelen ser consultados y actualizados constantemente.
La mayoría de las bases de datos se almacenan en las llamadas memorias secundarias, especialmente discos duros, aunque, en principio, pueden emplearse también discos ópticos, memorias flash, etc.
Las razones por las cuales las bases de datos se almacenan en memorias secundarias son:
· En general, las bases de datos son demasiado grandes para entrar en la memoria primaria.
· La memoria secundaria suele ser más barata que la memoria primaria (aunque esta última tiene mayor velocidad).
· La memoria secundaria es más útil para el almacenamiento de datos permanente, puesto que la memoria primaria es volátil.
3.1.2.- Definición y Creación del Espacio Asignado para cada Base de Datos
Las bases de datos se almacenan en ficheros o archivos. Existen diferentes formas de organizaciones primarias de archivos que determinan la forma en que los registros de un archivo se colocan físicamente en el disco y, por lo tanto, cómo se accede a éstos.
Las distintas formas de organizaciones primarias de archivos son:
· Archivos de Montículos (o no Ordenados): esta técnica coloca los registros en el disco sin un orden específico, añadiendo nuevos registros al final del archivo.
· Archivos Ordenados (o Secuenciales): mantiene el orden de los registros con respecto a algún valor de algún campo (clave de ordenación).
· Archivos de Direccionamiento Calculado: utilizan una función de direccionamiento calculado aplicada a un campo específico para determinar la colocación de los registros en disco.
· Árboles B: se vale de la estructura de árbol para las colocaciones de registros.
· Organización Secundaria o Estructura de Acceso Auxiliar: Estas permiten que los accesos a los registros de un archivo basado en campos alternativos, sean más eficientes que los que han sido utilizados para la organización primaria de archivos.
El DBMS asigna espacio de almacenamiento a las bases de datos cuando los usuarios introducen create database o alter database. El primero de los comandos puede especificar uno o más dispositivos de base de datos, junto con la cantidad de espacio en cada uno de ellos que será asignado a la nueva base de datos.
Si se utiliza la palabra clave default o se omite completamente la cláusula on, el DBMS pone la base de datos en uno o más de los dispositivos predeterminados de base de datos especificados en master.sysdevices.
Para especificar un tamaño (por ejemplo, 4MB) para una base de datos que se va a almacenar en una ubicación predeterminada, se utiliza: on default = size de esta forma:
create database newpubs on default = 4
3.1.3.- Bitácoras
Son estructuras ampliamente utilizadas para grabar las modificaciones de la base de datos.
Cada registro de la bitácora escribe una única escritura de base de datos y tiene lo siguiente:
· Nombre de la Transacción: Nombre de la transacción que realizó la operación de escritura.
· Nombre del Dato: El nombre único del dato escrito.
· Valor Antiguo: El valor del dato antes de la escritura.
· Valor Nuevo: El valor que tendrá el dato después de la escritura.
Es fundamental que siempre se cree un registro en la bitácora cuando se realice una escritura antes de que se modifique la base de datos.
También tenemos la posibilidad de deshacer una modificación que ya se ha escrito en la base de datos, esto se realizará usando el campo del valor antiguo de los registros de la bitácora.
Los registros de la bitácora deben residir en memoria estable como resultado el volumen de datos en la bitácora puede ser exageradamente grande.
La instrucción en MySQL para crear una bitácora en .txt se crea antes de acceder a la base de datos con la instrucción:
"xampp>mysql>bin>mysql -hlocalhost -uroot --tee=C:bitacora.txt"
La bitácora debe registrar todos los movimientos (insertar, eliminar y modificar) que se realicen en las tablas de la base de datos. Para lograr lo anterior es necesario crear un trigger para que se ejecute después de la operación de insertar, otro para después de eliminar y el último para después de modificar para cada una de las 3 tablas de la base de datos.
3.1.4.- Particiones
Cuando alguna de las tablas de una base de datos llega a crecer tanto que el rendimiento empieza a ser un problema, es hora de empezar a conocer algo sobre optimización. Una característica de MySQL son las particiones.
Particionar tablas en MySQL nos permite rotar la información de nuestras tablas en diferentes particiones, consiguiendo así realizar consultas más rápidas y recuperar espacio en disco al borrar los registros. El uso más común de particionado es según la fecha.
Para ver si nuestra base de datos soporta particionado simplemente ejecutamos:
SHOW VARIABLES LIKE '%partition%';
Se puede particionar una tabla de 5 maneras diferentes:
· Por Rango: para construir las particiones se especifican rangos de valores.
ALTER TABLE contratos
PARTITION BY RANGE (YEAR (fechaInicio)) (
PARTITION partDecada80 VALUES LESS THAN (1990),
PARTITION partDecada90 VALUES LESS THAN (2000),
PARTITION partDecada00 VALUES LESS THAN (2010),
PARTITION partDefault VALUES LESS THAN MAXVALUE
);
La última partición (partDefault) tendrá todos los registros que no entren en las particiones anteriores. De esta manera nos aseguramos que la información nunca dejará de insertarse en la tabla.
· Por Listas: para construir nuestras particiones especificamos listas de valores concretos.
ALTER TABLE contratos
PARTITION BY LIST (YEAR (fechaInicio)) (
PARTITION partDecada80 VALUES IN (1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989),
PARTITION partDecada90 VALUES IN (1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999),
PARTITION partDecada00 VALUES IN (2000, 2001, 2002, 2003, 2004, 2005, 2006,
2007, 2008, 2009),
PARTITION partDecada10 VALUES IN (2010, 2011, 2012, 2013, 2014, 2015, 2016,
2017, 2018, 2019)
);
· Por Hash: MySQL se encarga de distribuir las tuplas automáticamente usando una operación de módulo. Sólo hay que pasarle una columna o expresión que resulte en un entero (el hash) y el número de particiones que queramos crear.
ALTER TABLE contratos
PARTITION BY HASH (YEAR (fechaInicio))
PARTITIONS 7;
· Por Clave: similar a la partición por hash, pero en este caso no necesitamos pasarle un entero; MySQL utilizará su propia función de hash para generarlo. Si no se indica ninguna columna a partir de la que generar el hash, se utiliza la clave primaria por defecto.
ALTER TABLE contratos
PARTITION BY KEY ()
PARTITIONS 7;
· Compuesta: podemos combinar los distintos métodos de particionado y crear particiones de particiones
Borrar Particiones
Lo bueno de trabajar con particiones es que podemos borrar rápidamente registros sin tener que recorrer toda la tabla e inmediatamente recuperar el espacio en disco utilizado por la tabla.
Por ejemplo si queremos borrar la partición más antigua simplemente ejecutamos:
ALTER TABLE reports DROP PARTITION p201111;
Añadir particiones
En el ejemplo anterior las 2 últimas particiones creadas han sido:
PARTITION p201205 VALUES LESS THAN (TO_DAYS ("2012-06-01")),
PARTITION pDefault VALUES LESS THAN MAXVALUE
El problema es que todos los INSERT que se hagan después de mayo de 2012 se insertarán en pDefault. La solución sería añadir particiones nuevas para cubrir los próximos meses:
ALTER TABLE reports REORGANIZE PARTITION pDefault INTO (
PARTITION p201206 VALUES LESS THAN (TO_DAYS ("2012-07-01")),
PARTITION pDefault VALUES LESS THAN MAXVALUE);
En el caso que no tuviéramos una partición del tipo pDefault simplemente ejecutamos:
ALTER TABLE reports ADD PARTITION (PARTITION p201206 VALUES LESS THAN (TO_DAYS ("2012-07-01")));
Consultar Particiones
Para consultar información de particiones creadas en una tabla así como también los registros que contiene cada una ejecutamos:
SELECT PARTITION_NAME, TABLE_ROWS FROM information_schema.PARTITIONS WHERE TABLE_NAME='reports';
3.1.5.- Espacios Privados
Un “espacio privado” permite que los administradores y redactores gestionen el conjunto de datos del sitio. Algunas bases de datos tienen estos espacios privados llamados comúnmente paneles de control, que son formularios que aparecen al abrir la base de datos.
Los paneles de control sirven de "puerta principal" o "recibidor" de una base de datos en el sentido de que dirigen a las personas hacia determinadas tareas, como introducir o buscar datos. Sirven también para mantener alejados a los usuarios de las tablas que contienen los datos en tiempo real.
Cuando se recibe una base de datos, se averiguar cómo están estructurados los datos, revisar de manera general el panel de control. Puede ofrecer algún indicio sobre las tareas que el diseñador de la base de datos consideró que realizarían los usuarios habitualmente con los datos.
3.1.6.- Espacios para Objetos
Los DBMS se basan en archivos para almacenar datos, y estos archivos, o conjuntos de datos, residen en medios de almacenamiento, o dispositivos. Una buena parte del trabajo del DBA implicará la planificación para el almacenamiento real de la base de datos.
El rendimiento de la base de datos depende de la entrada y salida a disco. La cantidad de datos almacenados es mayor que nunca antes, y los datos son almacenados por más tiempo.
Algunos DBMS permiten al tamaño de los archivos temporales de expandirse y contraerse de forma automática. Dependiendo del tipo y la naturaleza de las operaciones de base de datos en proceso, esta fluctuación puede provocar picos de uso del disco.
Hay muchos problemas de almacenamiento que deben ser resueltos antes de que un DBA pueda crear una base de datos. Uno de los temas más importantes es la cantidad de espacio para permitir la base de datos.
El cálculo espacial debe tener en cuenta no sólo tablas, índices, sino también, y dependiendo del DBMS, el registro de transacciones. Cada una de estas entidades probablemente requerirá un archivo separado o conjunto de datos, para el almacenamiento persistente.
El DBA debe separar en diferentes discos a los archivos para:
· Mejorar el rendimiento
· Separar índices de datos
· Aislar los logros en otro disco
3.2 Segmentos
Los datos en la BD son almacenados físicamente en bloques Oracle: la mínima unidad de espacio físico, y es un múltiplo del bloque del SO (2 Kb usualmente). El tamaño del bloque Oracle se fija por el parámetro DB_BLOCK_SIZE del fichero init.ora. Un tamaño grande de bloque mejora la eficiencia del cache de E/S, pero el tamaño de la SGA aumentará para contener los mismos DB_BLOCK_BUFFERS, lo que significa un problema de memoria.
Una serie de bloques contiguos es una extensión, que es una unidad lógica de almacenamiento. Una serie de extensiones es un segmento. Cuando un objeto es creado, se reserva una extensión en su segmento. Cuando el objeto crezca, necesitará más espacio y se reservarán más extensiones.
Cada segmento tiene un conjunto de parámetros de almacenamiento que controla su crecimiento:
initial: tamaño de la extensión inicial (10k).
next: tamaño de la siguiente extensión a asignar (10k).
minextents: número de extensiones asignadas en el momento de la creación del segmento (1).
maxextents: número máximo de extensiones (99).
pctincrease: Porcentaje en el que crecerá la siguiente extensión antes de que se asigne, en relación con la última extensión utilizada (50).
pctfree: porcentaje de espacio libre para actualizaciones de filas que se reserva dentro de cada bloque asignado al segmento (10).
pctused: porcentaje de utilización del bloque por debajo del cual Oracle considera que un bloque puede ser utilizado para insertar filas nuevas en él.
tablespace: nombre del espacio de tablas donde se creará el segmento.
Cuando se diseña una BD se ha de tener mucho cuidado a la hora de dimensionar la BD y prever el crecimiento de las tablas. A continuación se hacen algunas consideraciones sobre la gestión del espacio para los diferentes segmentos.
Segmentos de Datos
El espacio del diccionario de datos se suele mantener más o menos constante, aunque es crítico que tenga suficiente espacio para crecer en el espacio de tablas SYSTEM. Así, hay que tener cuidado de colocar las tablas de usuario, los índices, segmentos temporales y los segmentos de rollback en otros espacios de tablas.
Además, es recomendable que el espacio de tablas SYSTEM esté al 50% o 75% de su espacio disponible. Finalmente, asegurarse que los usuarios no tienen privilegios de escritura en el espacio de tablas SYSTEM.
Las tablas crecen proporcionalmente con el número de filas, ya que se puede suponer que la longitud de las filas es constante.
Segmentos de Índice
Los índices crecen en tamaño en mayor proporción que las tablas asociadas si los datos en la tabla son modificados frecuentemente. La gestión del espacio es mejor si se mantienen los índices de tablas grandes en espacios de tablas separados.
Segmentos de Rollback
Los segmentos de rollback almacenan la imagen anterior a una modificación de un bloque. La información en el segmento de rollback se utiliza para asegurar la consistencia en lectura, el rollback (el valor en el segmento de rollback se copia en el bloque de datos) y la recuperación.
Es importante comprender cuál es el contenido de un segmento de rollback. No almacenan el bloque de datos modificado entero, sólo la imagen previa de la fila o filas modificadas. La información del segmento de roolback consiste en varias entradas llamadas undo. Por ejemplo, si se inserta una fila en una tabla, el undo necesitará sólo el rowid de la fila insertada, ya que para volver atrás la insercion sólo hay que realizar un delete. En las operación de actualización, se almacenará el valor antiguo de las columnas modificadas. El segmento de rollback asegura que la información undo se guardan durante la vida de la transacción.
Un segmento de rollback como cualquier otro segmento consiste en una serie de extensiones. Sin embargo, la mayor diferencia entre un segmento de datos y otro rollback es que en este último las extensiones se utilizan de manera circular. Así, habrá que tener cuidado a la hora de fijar el tamaño del segmento de rollback para que la cabeza no pille a la cola.
Segmentos Temporales
Los segmentos temporales se crean cuando se efectuan las siguientes operaciones:
Create Index
Select con distinct, order by, union, intersect y minus.
uniones no indexadas.
Ciertas subconsultas correlacionadas.
Si las tablas a ordenar son pequeñas la ordenación se realiza en memoria principal, pero si la tabla es grande se realiza en disco. El parámetro SORT_AREA_SIZE determina el lugar donde se hace la ordenación. Incrementándole se reduce la creación de segmentos temporales.
3.3 Definición de Memoria Compartida
Un servidor Oracle es un sistema que permite administrar bases de datos y que ofrece un medio de gestión de información abierto, completo e integrado.
Un servidor Oracle está constituido de una instancia y una base de datos.
Instancia de Oracle
Una instancia de Oracle permite acceder a la base de datos Oracle y permite abrir únicamente una sola base de datos.
La instancia de Oracle está compuesta de:
Procesos en segundo plano que administran y aplican las relaciones entre las estructuras físicas y las estructuras de memoria. Existen dos categorías:
· Procesos en Segundo Plano Obligatorios: DBWN, PMON, CKPT, LGWR, SMON
· Procesos en Segundo Plano Facultativos: ARCn, LMDn, RECO, CJQ0, LMON, Snnn, Dnnn, Pnnn, LCKn, QMNn
Estructuras de Memoria: compuestas básicamente de dos áreas de memoria: el área de memoria asignada a la SGA (System Global Area): asignada al inicio de la instancia y representa un componente fundamental de una instancia de Oracle.
Está compuesta de varias áreas de memoria:
Área de memoria compartida
Buffer caché de la base de datos
Log buffer
Así como otras estructuras para la gestión de bloqueos externos (lock), internos (match), datos estadísticos, etc.
Eventualmente también es posible configurar al nivel de la SGA
Área de memoria LARGE POOL
Área de memoria Java
Área de Memoria Asignada a la PGA (Program Global Area): Ésta es asignada al inicio del proceso de servidor. Es reservada a cada proceso de usuario que se conecte a la base de datos Oracle y liberada al final del proceso.
El Proceso de Usuario: Es el programa que solicita una interacción con la base de datos iniciando una conexión. Se comunica únicamente con el proceso de servidor correspondiente.
El Proceso de Servidor
Representa el programa que entra directamente en interacción con el servidor Oracle. Responde a todas las peticiones y envía los resultados. Puede estar dedicado a un servidor cliente o compartido por varios.
3.4 Definición de Múltiples Instancias de un DBMS
Cuando comenzamos a trabajar con Oracle una de las primeras cosas que aprendemos es a diferenciar entre estos conceptos: base de datos, instancia e instancia de base de datos.
Una instancia es el conjunto de procesos que se ejecutan en el servidor así como la memoria que comparten para ello.
Cuando se habla de base de datos, nos referimos a los archivos físicos que componen nuestra base de datos.
Si queremos referirnos a los procesos que se ejecutan en memoria como a los archivos de base de datos tendremos que utilizar el término instancia de base de datos.
La instancia en Oracle describe varios procesos residentes en la memoria del computador(es) y un área de memoria compartida por aquellos procesos. En arquitecturas de bases de datos tales como, Microsoft SQL Server e IBM BD2, la palabra instancia indica una colección de bases de datos que comparten recursos de memoria en común, o sea, la relación entre instancia y bases de datos es 1 a N. Pero la relación entre la instancia de Oracle y la base de datos es 1 a 1 o n a 1. Cuando hay una relación N a 1, la configuración es llamada RAC (Real Application CLuster), donde la base de datos reside en discos compartidos y las instancias en múltiples computadores anexados a la base de datos.
La instancia de Oracle es el motor que procesa los requerimientos de datos desde la base de datos. Está compuesta por procesos en primer plano, en segundo plano y un área de memoria compartida (SGA).
Una instancia de Oracle es un conjunto de estructuras de memoria que están asociadas con los archivos de datos (datafiles) en una máquina. Una base de datos es una colección de archivos físicos.
Instancia de Oracle
La integran los procesos 'background' y la SGA. Abre una y sólo una BDO, y permite acceder a ella.
Nota: con Oracle Real Application Cluster (RAC), más de una instancia usarán la misma BD.
En la máquina donde reside el servidor Oracle, la variable ORACLE_SID identifica a la instancia con la que estamos trabajando.
Vistas
V$DATABASE (Base de datos).
V$INSTANCE (Instancia).
V$SGA (SGA).
V$SGAINFO (Gestión dinámica de la SGA).
V$SGASTAT (SGA detallada).
V$BUFFER_POOL (Buffers en la caché de datos)
V$SQLAREA (Sentencias SQL).
V$PROCESS (Procesos).
V$BGPROCESS (Procesos background).
V$DATAFILE (Ficheros de datos de la BD).
V$CONTROLFILE (Ficheros de control de la BD).
V$LOGFILE (Ficheros redo log de la BD).
DBA_TABLESPACES (Tablespaces de la BD).
DBA_SEGMENTS (Segmentos que hay en los tablespaces).
DBA_EXTENTS (Extensiones que componen los segmentos).
DBA_USERS (Usuarios de la BD).
Oracle RAC(Real Application CLuster).
En un Rac de Oracle, múltiples instancias permiten el acceso a una única Base de datos. En un RAC las instancias corren en múltiples Nodos (servidores), y acceden a un conjunto común de datafiles que comprender a una 'Única' Base de datos."
En contraste, en un ambiente de una única instancia, una base de datos Oracle es usada por sólo UNA Instancia corriendo en el servidor. Por lo Tanto, los usuarios accediendo a la base de datos pueden conectarse a ésta, sólo a través de ese 'Único' servidor.
En un Oracle RAC, una base de datos puede ser montada por más de una instancia, y en cualquier punto, una instancia será parte de sólo una Base de datos. El almacén no volátil para archivos de datos que comprende la Base de datos es igualmente disponible a todos los nodos, para el acceso de lectura y escritura. De lo anterior se desprende que un RAC de Oracle necesita coordinar y regular el acceso “simultaneo” a los datos desde múltiples servidores (nodos), por ende, debe existir una red privada que sea eficiente, confiable y de alta rapidez, entre los nodos del clúster para enviar y recibir datos
Crear Instancias MySQL
Tener dos instancias o más tiene entre otras las siguientes justificaciones. Una se dedicará a desarrollo, para hacer las modificaciones y pruebas necesarias y otra al de producción.
Proceso
Copiar la carpeta data que se encuentra en nuestro caso en c:\MySQL, como data2
Copiar y pegar la configuración de MySQL. Es decir, del archivo my.ini (en linux my.cnf) generamos una copia que podría llamarse my2.ini.
Ahora con cuidado editamos my2.ini, procure no tocar my,ini a menos que este seguro de lo que hace.
Iniciamos configurando el puerto por donde escuchara MySQL la segunda instancia y la ruta de datos el archivo de datos.
Iniciar Instancia desde Consola
Desde la consola de ms-dos en modo administrador. [Tecla Win] + [X] y damos clic en Símbolo de Sistema (Administrador). Ahora introduzca desde la línea de comandos:
cd /MySQL/MySQL Server 5.6/bin
mysqld --defaults-file=my2.ini --explicit_defaults_for_timestamp = TRUE
mysql -u root -port 3307 -p
Establecer la Instancia como Servicio
Procederemos a instalar la nueva instancia como servicio. Desde la consola de ms-dos en modo administrador. En windows 8 pulse la [Tecla Win] + [X] y damos clic en Símbolo de Sistema (Administrador):
martes, 26 de febrero de 2019
Practica djangogirls
Creamos un proyecto

archivos creados en el proyecto

Creamos una palicacion

"Setting"En Installed_APP le agregamos nuestra aplicación

En model agregamos el codigo siguiente
from django.db import models from django.utils import timezone class Post(models.Model): author = models.ForeignKey('auth.User', on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField() created_date = models.DateTimeField( default=timezone.now) published_date = models.DateTimeField( blank=True, null=True) def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.title


Agregar nuestro nuevo modelo a la base de datos, luego migramos los modelos
En admin.py ponemos el siguiente codigo
from django.contrib import admin from .models import Post admin.site.register(Post)

Corremos nuestro servidor, para ver si funciono vamos ingresamos en el url http://127.0.0.1:8000
y http://127.0.0.1:8000/admin/ para ingresar con nuestro usuario



Creamos un usario para entrar



ctrl+c para cerrar el servidor

martes, 19 de febrero de 2019
1.1 Administrador de base de datos
DBA es también una abreviatura en inglés para “hacer negocios como” (doing business as), un término usado a veces en la escritura de negocios y legal. dBA es una abreviatura de decibelios con ponderación.
Un administrador de base de datos (DBA) dirige o lleva a cabo todas las actividades relacionadas con el mantenimiento de un entorno de base de datos exitoso. Las responsabilidades incluyen el diseño, implementación y mantenimiento del sistema de base de datos; el establecimiento de políticas y procedimientos relativos a la gestión, la seguridad, el mantenimiento y el uso del sistema de gestión de base de datos; y la capacitación de los empleados en la gestión y el uso de las bases de datos. Se espera que un DBA se mantenga al tanto de las nuevas tecnologías y los nuevos enfoques de diseño. Típicamente, un DBA tiene ya sea un título en Ciencias de la Computación y algún tipo de entrenamiento en el puesto de trabajo con un producto particular de base de datos o una experiencia más amplia con una gama de productos de base de datos. Por lo general, se espera que un DBA tenga experiencia con uno o más de los principales productos de gestión de base de datos, tales como Structured Query Language, SAP y software de gestión de bases de datos basado en Oracle.
Un administrador de base de datos (DBA) dirige o lleva a cabo todas las actividades relacionadas con el mantenimiento de un entorno de base de datos exitoso. Las responsabilidades incluyen el diseño, implementación y mantenimiento del sistema de base de datos; el establecimiento de políticas y procedimientos relativos a la gestión, la seguridad, el mantenimiento y el uso del sistema de gestión de base de datos; y la capacitación de los empleados en la gestión y el uso de las bases de datos. Se espera que un DBA se mantenga al tanto de las nuevas tecnologías y los nuevos enfoques de diseño. Típicamente, un DBA tiene ya sea un título en Ciencias de la Computación y algún tipo de entrenamiento en el puesto de trabajo con un producto particular de base de datos o una experiencia más amplia con una gama de productos de base de datos. Por lo general, se espera que un DBA tenga experiencia con uno o más de los principales productos de gestión de base de datos, tales como Structured Query Language, SAP y software de gestión de bases de datos basado en Oracle.
Gestión General de Base de Datos
Modelado de Datos y Diseño de Base de Datos
Auditoria
Integración con aplicaciones
Resguardo y recuperación de datos
Inteligencia de negocios y almacenamiento de datos
Planificación de capacidad
Administración de cambios
Desarrollo de aplicaciones
Modelado de Datos y Diseño de Base de Datos
Auditoria
Integración con aplicaciones
Resguardo y recuperación de datos
Inteligencia de negocios y almacenamiento de datos
Planificación de capacidad
Administración de cambios
Desarrollo de aplicaciones
El DBA es la persona con más conocimientos sobre base de datos en una organización. Como tal, debe entender las reglas básicas de la tecnología de base de datos relacional y ser capaz de comunicarlos con precisión a los demás.
Un DBA debe ser un profesional experto en la recopilación y análisis de las necesidades del usuario para obtener modelos de datos conceptuales y lógicos. Esta tarea es más difícil de lo que parece. Un modelo conceptual de datos describe los requisitos de datos a un nivel muy alto, un modelo de datos lógico proporciona en profundidad los detalles de los tipos de datos, longitudes, relaciones y cardinalidad. El DBA utiliza técnicas de normalización para ofrecer modelos de datos que reflejen las necesidades de los datos de la empresa.
Una de las tareas de un DBA es identificar qué usuarios tienen acceso a insertar, actualizar o eliminar datos, y cuándo. Una auditoría NO sólo podría ser necesaria por un tiempo limitado, para usuarios específicos o datos específicos. También puede ser requerida 24/7 para todos los datos que se introduzcan en el DBMS. Regularmente, para realizar las funciones de autorías los DBAs tienen que trabajar en combinación con los auditores internos y externos de la empresa.
La mayoría de las empresas hoy en día utilizan aplicaciones de terceros (casi nadie ya desarrolla sus propias aplicaciones in-house), muy pocas de estas aplicaciones funcionan de manera aislada. En otras palabras, las aplicaciones tienen que interconectarse unas con otras, generalmente utilizando base de datos como el medio para compartir los datos. Los DBAs a menudo se involucran en los procesos de integrar las aplicaciones existentes con las bases datos que administran. Esto puede incluir la creación de aplicaciones a medida, scripts, etc.
Uno de los aspectos más fundamentales del trabajo del DBA es proteger los datos de la organización. Esto incluye hacer copias de seguridad periódicas de los datos y mantenerlos a salvo de la destrucción accidental o intencional. Además, diseñar, implementar y probar un plan de recuperación para que cuando se presenten los problemas, los datos se pueden restaurar rápidamente.
Una de las áreas de mayor crecimiento para el DBA es la Inteligencia de Negocios (BI) y almacenamiento de datos. Esto se debe a que cada vez más organizaciones están tratando de extraer toda la información que pueda con el fin de tomar mejores decisiones de negocios.
En la mayoría de las organizaciones, el número y tamaño de las bases de datos crece rápidamente. Es la responsabilidad del DBA gestionar el creciente volumen de datos y diseñar los planes apropiados para administrarlos. Esto incluye también la gestión del hardware donde se almacenan los datos.
La configuración del servidor SQL Server o MySQL, el esquema de base de datos, el código de Transact-SQL, y muchas otras facetas del ecosistema de aplicaciones cambian con el tiempo. A menudo es la responsabilidad del DBA realizar el análisis de impacto antes de realizar los cambios dentro de una DBMS. Implementar cambios, hacer pruebas piloto y documentar todos los cambios y procedimientos es parte del trabajo de un DBA.
Muchos administradores de base datos deben de desarrollar aplicaciones y scripts con el objetivo de automatizar tareas relacionadas con la inserción, sustracción o borrado de información dentro del manejador de base de datos. En general, éste debe de colaborar a nivel de integración de sistema con los desarrolladores de aplicaciones, por lo que a veces se ve en la obligación de desarrollar código para casos específicos.
Suscribirse a:
Comentarios (Atom)